【忙しいアピール定期】仕事が終わらねぇ… [徒然日記]
7月中締め切りの仕事が終わる気がまったくしない。最近はコロナ禍が広がりつつある上、天気もずーーと悪いので、外出で気晴らしもできず、気分も盛り上がらず、どうしても煮詰まってしまいます。

もともと夏休みの宿題は最終週に片付けるタイプなので、締め切りがないと集中できない性分なんですよね。コロナ前は展示会や報告会、学会などがあるのでそれがモチベーションとなっていましたが、今はそれがないのでダラダラ仕事。生産性ワル…。
なんか、切羽詰まったときの集中力を呼び出す良い方法ないかなぁ。ストレスたまりそうだけど。
(´・ω・`)

- 作者: 苫米地英人
- 出版社/メーカー: コグニティブリサーチラボ株式会社
- 発売日: 2014/04/14
- メディア: Kindle版

- 作者: 中島聡
- 出版社/メーカー: 文響社
- 発売日: 2016/06/01
- メディア: 単行本(ソフトカバー)
")
マンガでわかる 「仕事が速い人」と「仕事が遅い人」の習慣 (Asuka business & language book)
- 出版社/メーカー: 明日香出版社
- 発売日: 2018/06/12
- メディア: 単行本(ソフトカバー)
【惑星コロニー】人類が目指すべきは火星ではなく金星なのでは? [トンデモ学説]

それに加え、スペースXは火星にコロニーを作ることを真剣に検討しています。まさに火星探査ラッシュと言ってよい状態なのですが、はたして火星は人類が目指すのに相応しい星なのでしょうか?

火星は、重力が小さい、大気は薄い、また固有磁場もないので薄い大気を貫く放射線が直接降り注いできます。そして何より寒い。平均気温で-55度です。大量の水もあまり期待できないでしょう。

地球に比べ、かなり過酷な世界と言わざるえません。テラフォーミングできたとしても活用できる資源が限られるため、かなり狭い領域となってしまうでしょう。まさに砂漠のオアシスですね。
本当に火星が人類にとってベストな移住先なのか?という疑問をもっていたら、こんな記事を見つけました!
人類は火星の前に金星を目指した方が良さそうな理由とは?
https://gigazine.net/news/20180315-venus-before-mars/

この記事によると、金星の地表上空50kmの場所では、気圧はほぼ1気圧。そして気温も30~50度と暑い夏程度。多くの放射線も大気が防いでくれます。そして大気中には硫酸だけでなく、二酸化炭素、窒素、水素も多く含むため、大量の水や作物の肥料を生成することもできます。
NASAは、飛行船型の探査機を飛ばす計画もたてているようです。

https://io9.gizmodo.com/how-nasa-could-build-a-cloud-city-over-venus-1672240059
しかし、そこで大きな障害となるのは金星固有の大気の流れである「スーパーローテーション」です。地球でいう偏西風のようなものですが、風速が桁違い。4日で金星を一周する速さです。偏西風は秒速30mに対し、スーパーローテーションは秒速100m。そして金星全体を覆っています。
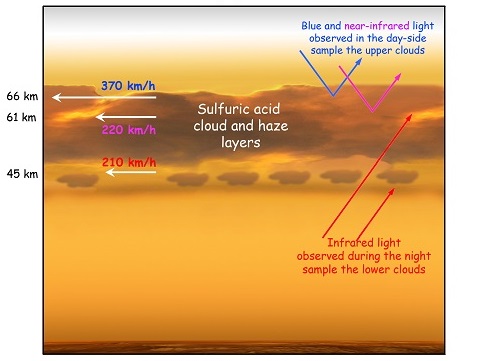
https://andymaypetrophysicist.com/can-earth-become-venus/
これを克服する術が見つかれば、計画も具体化するかもしれませんね。日本の金星探査機「あかつき」が収集したデータの研究成果が重要になってきそうです。
金星への移住というと地表を思い浮かべる人がほとんどだと思いますが、金星の地表は90気圧。地球で言うなら海底の気圧と比べるようなものです。
となると1気圧の空気を充満した飛行船は海の上の船のようなもので、気圧を保っていれば沈むことはありません。濃硫酸の雲も問題ですが、金星の大気に酸素がほとんどないので、金属が腐食することはありません。気球や宇宙服を金属で覆っても大丈夫でしょう。
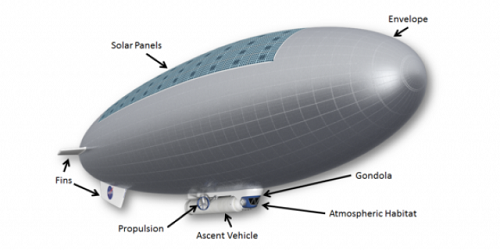
https://www.starletters.com/2018/06/18/is-a-human-mission-to-the-clouds-of-venus-possible/
飛行船内にある水や酸素は金星の外気に漏れ出ると非常に危険ですが、すでに人類は地球環境では非常に危険な水素やガソリンを安全に活用できる技術を身に着けています。克服できない課題ではないと思います。
一番の問題は、荒れ狂うスーパーローテーションですが、これも金星の気象をよく調べれば安全に飛行船を運用できる方法が見つかるでしょう。金星では天気予報が非常に重要になりそうですね。

https://www.starletters.com/2018/06/18/is-a-human-mission-to-the-clouds-of-venus-possible/
資源が乏しい火星でコロニーを作るよりも、資源が豊富な金星で「ラピュタの城」を作ったほうがよっぽど現実的だと思います。日本はここで火星探査のブームに乗るのではなく、金星探査に力を入れてほしいところですね。
(^^)/~
")
惑星気象学入門――金星に吹く風の謎 (岩波科学ライブラリー)
- 作者: 松田 佳久
- 出版社/メーカー: 岩波書店
- 発売日: 2011/08/26
- メディア: 単行本(ソフトカバー)
")
ここまでわかった! 太陽系のなぞ: 探査機の写真で見えてきたおどろきの姿 (子供の科学★サイエンスブックス)
- 出版社/メーカー: 誠文堂新光社
- 発売日: 2014/11/05
- メディア: 大型本
")
大人のプラモランドVOL.5 金星探査機あかつき&宇宙帆船イカロス<蓄光版> (ロマンアルバム)
- 出版社/メーカー: 徳間書店
- 発売日: 2011/07/04
- メディア: ムック
コロナの最新状況と第二波は来るのか? [徒然日記]
陽性件数はうなぎのぼりですね。これを見ると只事ではありません。
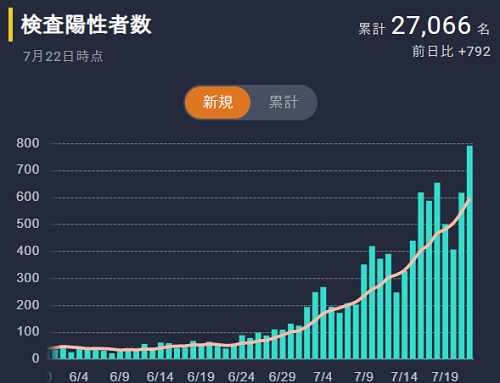
PCR件数も増えています。傾向は陽性件数と明らかに相関ありですね。検査数が減っている時には陽性件数も減っています。市内の一定数に陽性者がいるということの証でしょう。
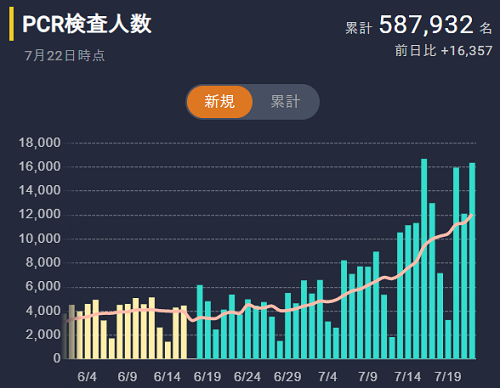
再生産数を見てみましょう。前回 1.7 まであがっていましたが、1.4程度で数値が安定しています。PCR件数も増えているので、これが現在の日本のライフスタイルでの市中感染力の実態と考えてよさそうです。陽性者数が増えてきて、多くの人が警戒しはじめたのではないかと思います。
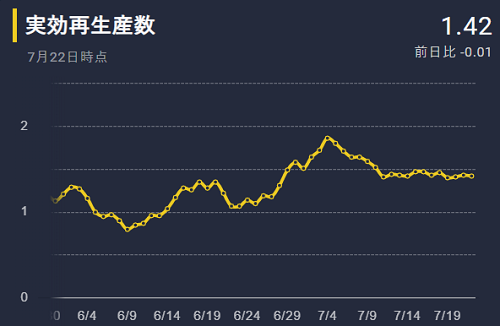
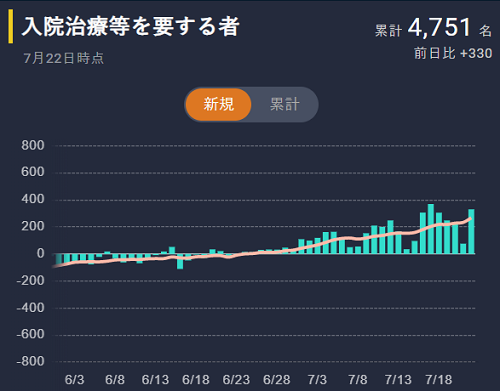
陽性者が増えていますので要入院治療者も着実に増えています。
重傷者も増加傾向ですね。あまりよい傾向とは言えません。医療体制の整備が急がれますね。
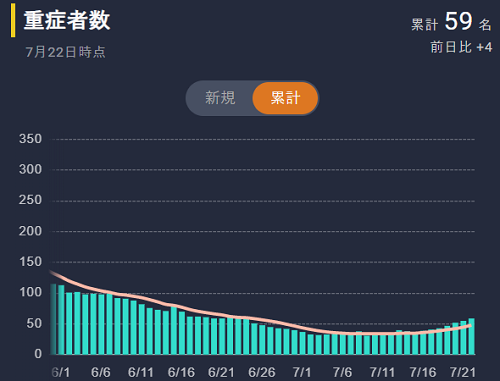
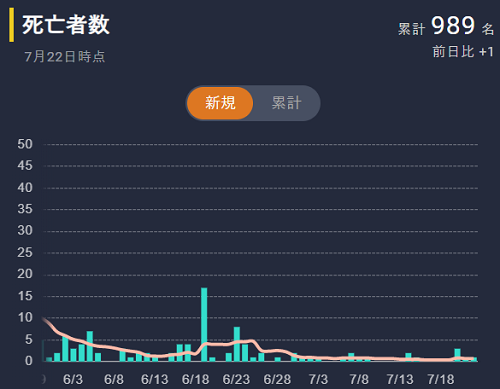
死亡者は少ないですが、重傷者が増加していますので今後徐々に増加していくものと思えます。
年齢分布を見るとやはり20代から50代の生産年齢の世代が多いようです。特に20代が突出しています。いわゆる夜の街含めサービス産業に携わっている世代が多くPCR検査が重点的に行われた結果かもしれません。
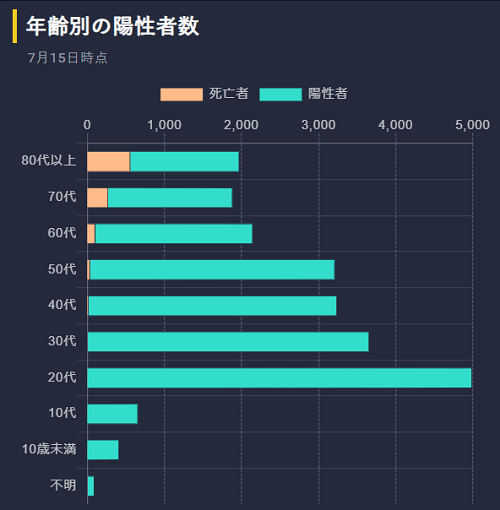
政府がGoToを企画している背景には、陽性者は増えているものの重傷者・死亡者が低レベルにあることが背景にあるようです。やはりコロナウイルスが弱毒化していると見ているようですね。
ただ、このまま楽観できるかというとそうではないと思っています。個人的な意見ですが、本当の第二波は今年の冬に来るのではないかと思います。なぜ冬に風邪が流行するのか、次のような解説がありました。以下抜粋です。
新たな研究で、冷たい空気に触れて体内温度が下がると、免疫系がウイルスを撃退する能力も低下することが示唆されました。「マウスの気道細胞をモデルとして用いて検討した結果、鼻の中程度の低い温度(33度前後)では、宿主の免疫系がウイルス増殖を阻止する防御シグナルを誘起できないことが分かった」「屋外の冷たい空気を吸い込むと、一時的に鼻の中の温度が下がり、冷たい外気温によってウイルスが増殖して風邪を引き起こす」冬になると風邪のみでなくRSウイルスも流行します。呼吸器合胞体ウイルス(RSV)は、感染すると、風邪のような症状を起こすウイルスです。ただし、乳幼児や高齢者では重篤になることもあるため、特に注意が必要です。
寒さにより風邪が引きやすくなるのは、鼻孔が冷えることにより免疫系機能が阻害されることが原因のようです。つまり、現在は弱毒化しているコロナウイルスも、冬には免疫力低下により急速に症状が悪化する可能性があります。油断はできません。
このまま対策をせずに全国にコロナウイルスが広まっていくと、冬にどうなるかが心配です。
(´・ω・`)

- 出版社/メーカー: 日経BP
- 発売日: 2020/06/02
- メディア: Kindle版

ウイルスと内向の時代 コロナ後の大転換を国家と個人はどう生き残るか
- 作者: 佐藤優
- 出版社/メーカー: 徳間書店
- 発売日: 2020/07/01
- メディア: Kindle版
")
コロナショック・サバイバル 日本経済復興計画 (文春e-book)
- 作者: 冨山 和彦
- 出版社/メーカー: 文藝春秋
- 発売日: 2020/04/30
- メディア: Kindle版
スペクトログラムの学習用データの生成を自動化する [AI]
前回と同じくデータは、”イチ”、”二”、”サン”の3つ。それに無音も認識が必要なので無音のノイズデータの4点です。学習用の画像データは32x32の大きさにしました。結果から出してしまいますが、次のようなデータが生成されました。
Python のスケッチを次にあげておきます。見通しをよくするために幾つか関数に分離をしていますが、前回のアルゴリズムをそのまま踏襲しています。追加した処理は、次の3点です。
(1) 無音時のノイズ処理(スペクトラムの範囲を決められない為)
(2) ランダムにシフト量とゲイン量を算出する処理
(3) スペクトラムをリサイズして画像として保存する処理
import numpy as np
import cv2 as cv
import random
import os
import scipy.io.wavfile as wav
from matplotlib import pyplot as plt
from numpy.lib import stride_tricks
from numpy.lib.stride_tricks import as_strided
from numpy.fft import rfft
""" short time fourier transform of audio signal """
def stft(samples, frameSize, overlapFac = 0.5, window = np.hanning):
win = window(frameSize)
hopSize = int(frameSize - np.floor(overlapFac * frameSize))
# cols for windowing
cols = np.floor(len(samples) / hopSize) - 1
# print("cols: ", cols)
# make an array in 2nd dimension with hopSize
frames = as_strided(samples, shape=(int(cols), frameSize), strides = (samples.strides[0] * hopSize, samples.strides[0])).copy()
frames = frames * win
return rfft(frames)
def spectrogram_detector(spectrogram):
spectro_mean = np.mean(spectrogram, axis=1)
threshold = np.ceil(np.mean(spectro_mean))
threshold = np.ceil(np.mean(spectro_mean[spectro_mean <= threshold])) # pick up only noise signals
print("threshold: ", threshold)
offset = 5
up_trigger = 0
down_trigger = 0
for i in range(offset, spectro_mean.shape[0]-offset):
cur_floor = int(np.mean(spectro_mean[i:i+offset-1]))
pre_floor = int(np.mean(spectro_mean[i-offset:i-1]))
if ((cur_floor > threshold) and (pre_floor <= threshold) and (up_trigger == 0)):
up_trigger = i
if ((cur_floor <= threshold) and (pre_floor > threshold)):
down_trigger = i
print("up_trigger : ", up_trigger)
print("down_trigger: ", down_trigger)
return up_trigger, down_trigger
def augmentator(spectrogram, left, right, signal):
axis_max = spectrogram.shape[0]
if (signal == 0): # in case of zero1.wav
left = random.randint(0, np.floor(axis_max/2))
right = random.randint(np.ceil(axis_max/2), axis_max-1)
left_or_right = random.randint(0,1)
if (left_or_right > 0): # 1 is right, 0 is left
move = random.randint(right, axis_max-1)
move = move - right
else:
move = random.randint(0,left)
move = -move
print("move: ", move)
spectrogram_result = spectrogram.copy()
spectrogram_body = spectrogram[left:right, :] # extract spectoram data
#if the shift is left, the value is minus, the shift is right, tha value is plus
if (move < 0):
spectrogram_noise = spectrogram[left+move:left,:]
spectrogram_result[left+move:right+move,:] = spectrogram_body
spectrogram_result[right+move:right,:] = spectrogram_noise
elif (move > 0):
spectrogram_noise = spectrogram[right:right+move,:]
spectrogram_result[left+move:right+move,:] = spectrogram_body
spectrogram_result[left:left+move,:] = spectrogram_noise
max_gain = 255 / np.max(spectrogram) # maximum gain
gain = random.uniform(0.67, max_gain)
print("gain: ", gain)
return spectrogram_result * gain
def plot_spectrogram(spectrogram, time_axis, freq_axis, time_interval, frequency_map):
plt.figure(figsize=(16, 8))
plt.imshow(np.transpose(spectrogram), origin="lower", aspect="auto", cmap="jet", interpolation="none")
plt.colorbar()
plt.xlabel("time (s)")
plt.ylabel("frequency (hz)")
plt.xlim([0, time_axis-1])
plt.ylim([0, freq_axis-1])
xlocs = np.float32(np.linspace(0, time_axis-1, 5))
plt.xticks(xlocs, ["%.02f" % i for i in (xlocs * time_interval)])
ylocs = np.int16(np.floor(np.linspace(0, freq_axis-1, 10)))
plt.yticks(ylocs, ["%.02f" % frequency_map[i] for i in ylocs])
plt.show()
def gen_spectrogram(wavfile, frameSize):
sample_rate, samples = wav.read(wavfile)
print("sample_rate:", sample_rate)
print("num_of_samples:", len(samples))
spectrogram = stft(samples, frameSize)
frequency_map = np.fft.fftfreq(frameSize, 1. / sample_rate)
spectrogram = 20. * np.log10(np.abs(spectrogram)) # amplitude to decibel
# spectrogaram has an extra colum, so slice it
spectrogram = spectrogram[:,:int(np.floor(frameSize/2))]
spectrogram -= np.min(spectrogram) # normalize
return spectrogram, sample_rate, frequency_map
def main():
frameSize = 256
output_img_size = 32
num_of_augdata = 5
wavfiles = ['./wav/zero1.wav', './wav/ichi1.wav', './wav/ni1.wav', './wav/san1.wav']
for i in range(len(wavfiles)):
print(wavfiles[i])
spectrogram, sample_rate, frequency_map = gen_spectrogram(wavfiles[i], frameSize)
time_dim, freq_dim = np.shape(spectrogram)
time_interval = frameSize / sample_rate
plot_spectrogram(spectrogram, time_dim, freq_dim, time_interval, frequency_map)
# detect the range of spectrogram signal
left, right = spectrogram_detector(spectrogram)
data_dir = "./" + str(i)
if not os.path.exists(data_dir):
os.mkdir(data_dir)
for n in range(num_of_augdata):
# spectrogram data augmentator
spectro_aug = augmentator(spectrogram, left, right, i)
# plot_spectrogram(spectro_aug, time_dim, freq_dim, time_interval, frequency_map)
spectro_aug.astype(np.uint8)
spectro_img = cv.resize(spectro_aug, (output_img_size, output_img_size))
spectro_img = np.rot90(spectro_img)
data_path = data_dir + "/" + str(n) + ".bmp"
cv.imwrite(data_path, spectro_img)
if __name__ == "__main__":
main()
おそらく実機では、マイクのノイズやゲイン量が大きく影響するので作り直しになると思いますが、このスケッチそのものはパラメータなどを変更することで流用できそうです。
(^^)/~

- 出版社/メーカー: コロナ社
- 発売日: 2018/04/04
- メディア: 単行本

データサイエンス教本 Pythonで学ぶ統計分析・パターン認識・深層学習・信号処理・時系列データ分析
- 出版社/メーカー: オーム社
- 発売日: 2019/01/18
- メディア: Kindle版

Pythonデータサイエンスハンドブック ―Jupyter、NumPy、pandas、Matplotlib、scikit-learnを使ったデータ分析、機械学習
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/05/26
- メディア: 単行本(ソフトカバー)
スペクトログラムの学習用データを生成する [AI]
そこで、既存データを加工して学習用データを生成したいと思います。このとき、生成するデータは、次の2つの要因を考慮する必要があります。
(1)音声が入ってくるタイミングはバラバラ
(2)キャプチャされる音声のレベルは一定でない
これらのデータを生成するには、得られたスペクトログラムを左右にランダムに降り、スペクトルのレベル(ゲイン)をランダムに変化させたデータを生成するのがよさそうです。
■ スペクトログラムのデータを左右に降る
スペクトログラムの信号が現れる位置と信号がなくなる位置を検出し移動できる量を特定します。左右に位置はランダムにずらします。そのときに、ずらした分のノイズは入れ替えます。
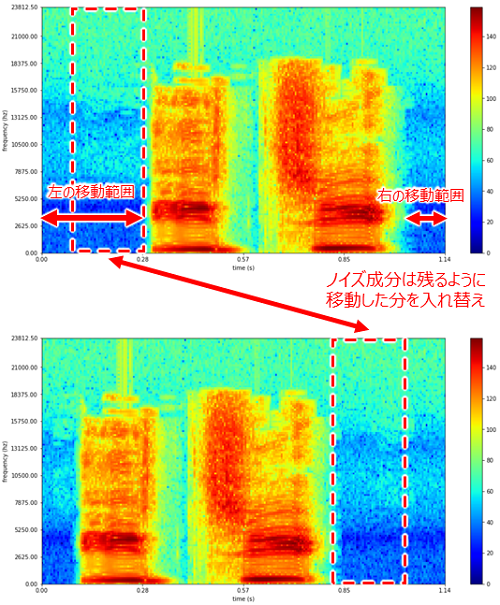
■ スペクトルのゲインを変化させる
スペクトルのゲインは、一旦ここでは最大値が255になるか、最小値はデータの最大値の2/3となるようにします。実際の運用では、最小値の値を使用するマイクにあわせたほうがいいでしょう。
■ スペクトログラムの data augumentation のPythonスケッチを書く
以上、2点に留意して検証用のPythonスケッチを作ってみました。まだお試しなのでパラメータは直打ちです。
import numpy as np
import scipy.io.wavfile as wav
from matplotlib import pyplot as plt
from numpy.lib import stride_tricks
from numpy.lib.stride_tricks import as_strided
from numpy.fft import rfft
times = 0
ftaps = 0
frameSize = 0
""" short time fourier transform of audio signal """
def stft(samples, frameSize, overlapFac = 0.5, window = np.hanning):
win = window(frameSize)
hopSize = int(frameSize - np.floor(overlapFac * frameSize))
# cols for windowing
cols = np.floor(len(samples) / hopSize) - 1
# print("cols: ", cols)
# make an array in 2nd dimension with hopSize
frames = as_strided(samples, shape=(int(cols), frameSize), strides = (samples.strides[0] * hopSize, samples.strides[0])).copy()
frames = frames * win
return rfft(frames)
def augmentator(spectrogram):
spectro_mean = np.mean(spectrogram, axis=1)
threshold = np.mean(spectro_mean)
threshold = np.mean(spectro_mean[spectro_mean <= threshold]) # pick up only noise signals
print("threshold: ", threshold)
up_trigger = 0
down_trigger = 0
for i in range(3, spectro_mean.shape[0]-3):
if ((np.mean(spectro_mean[i:i+2]) > threshold) and (np.mean(spectro_mean[i-3:i-1]) <= threshold) and (up_trigger == 0)):
up_trigger = i
if ((np.mean(spectro_mean[i:i+2]) <= threshold) and (np.mean(spectro_mean[i-3:i-1]) > threshold)):
down_trigger = i
print("up_trigger : ", up_trigger)
print("down_trigger: ", down_trigger)
move = -10 #if the shift is left, the value is minus, the shift is right, tha value is plus
spectrogram_result = spectrogram.copy()
spectrogram_body = spectrogram[up_trigger:down_trigger, :]
if (move < 0):
spectrogram_noise = spectrogram[up_trigger+move:up_trigger,:]
spectrogram_result[up_trigger+move:down_trigger+move,:] = spectrogram_body
spectrogram_result[down_trigger+move:down_trigger,:] = spectrogram_noise
elif (move > 0):
spectrogram_noise = spectrogram[down_trigger:down_trigger+move,:]
spectrogram_result[up_trigger+move:down_trigger+move,:] = spectrogram_body
spectrogram_result[up_trigger:up_trigger+move,:] = spectrogram_noise
gain = 255 / np.max(spectrogram) # maximum gain
# gain = 0.67 # minmum gain
return spectrogram_result * gain
def plot_spectrogram(spectrogram, time_axis, freq_axis, time_interval, frequency_map):
plt.figure(figsize=(16, 8))
plt.imshow(np.transpose(spectrogram), origin="lower", aspect="auto", cmap="jet", interpolation="none")
plt.colorbar()
plt.xlabel("time (s)")
plt.ylabel("frequency (hz)")
plt.xlim([0, time_axis-1])
plt.ylim([0, freq_axis-1])
xlocs = np.float32(np.linspace(0, times-1, 5))
plt.xticks(xlocs, ["%.02f" % i for i in (xlocs * time_interval)])
ylocs = np.int16(np.floor(np.linspace(0, freq_axis-1, 10)))
plt.yticks(ylocs, ["%.02f" % frequency_map[i] for i in ylocs])
plt.show()
def main():
frameSize = 256
sample_rate, samples = wav.read('./wav/ni1.wav')
print("sample_rate:", sample_rate)
print("num_of_samples:", len(samples))
spectrogram = stft(samples, frameSize)
frequency_map = np.fft.fftfreq(frameSize, 1. / sample_rate)
spectrogram = 20. * np.log10(np.abs(spectrogram)) # amplitude to decibel
# spectrogaram has an extra colum, so slice it
spectrogram = spectrogram[:,:int(np.floor(frameSize/2))]
time_dim, freq_dim = np.shape(spectrogram)
print(spectrogram.shape)
spectrogram -= np.min(spectrogram)
max_spectro = np.max(spectrogram) # normalize
print("MAX: ", max_spectro)
time_interval = frameSize / sample_rate
plot_spectrogram(spectrogram, time_dim, freq_dim, time_interval, frequency_map)
spectrogram = augmentator(spectrogram)
plot_spectrogram(spectrogram, time_dim, freq_dim, time_interval, frequency_map)
if __name__ == "__main__":
main()
少し工夫した点は、開始点 (up_trigger)、終了点(down_trigger)の判定に前後3ラインの出力の平均を使っているところです。これにより精度よく開始点と終了点を判別できるようになりました。
試しに、”イチ”、”二”、”サン”の音声データを加工してみました。
”イチ”
-a90de.png)
”二”
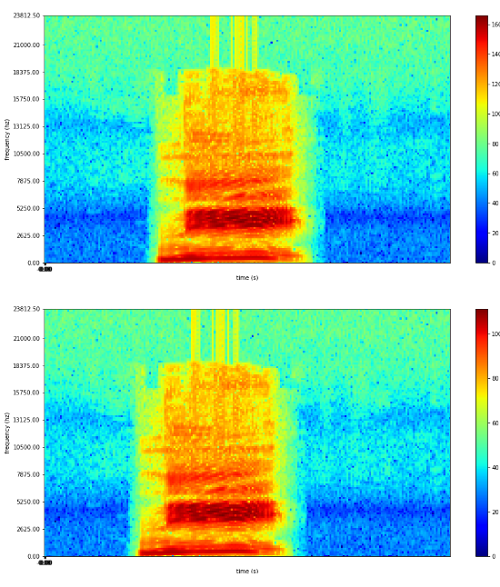
”サン”
-5ef38.png)
なかなかいい感じですね。ただ実際には、マイクのノイズの下限は一定になるので、ノイズのレベルもゲインを下げているのは現実的ではありません。それについては、実際にマイクの特性を見てから考えたいと思います。
次は、このデータを使って畳み込みニューラルネットワークで、"イチ"、"二"、"サン"を判定できるかチャレンジしてみたいと思います!
(^^)/~
")
NumPy&SciPy数値計算実装ハンドブック (Pythonライブラリ定番セレクション)
- 出版社/メーカー: 秀和システム
- 発売日: 2019/08/23
- メディア: 単行本
")
現場で使える! Python科学技術計算入門 NumPy/SymPy/SciPy/pandasによる数値計算・データ処理手法 (AI & TECHNOLOGY)
- 作者: かくあき
- 出版社/メーカー: 翔泳社
- 発売日: 2020/05/19
- メディア: 単行本(ソフトカバー)
Pythonデータサイエンスハンドブック ―Jupyter、NumPy、pandas、Matplotlib、scikit-learnを使ったデータ分析、機械学習
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/05/26
- メディア: 単行本(ソフトカバー)
Python で音声ファイルからスペクトログラムを生成してみた [AI]
その前処理として、Python を使って音声ファイルからスペクトログラムを生成するプログラムを作ってみました。
import numpy as np
import scipy.io.wavfile as wav
from matplotlib import pyplot as plt
from numpy.lib import stride_tricks
from numpy.lib.stride_tricks import as_strided
from numpy.fft import rfft
""" short time fourier transform """
def stft(samples, frameSize, overlapFac = 0.5, window = np.hanning):
win = window(frameSize)
hopSize = int(frameSize - np.floor(overlapFac * frameSize))
# cols for windowing
cols = np.floor(len(samples) / hopSize) - 1
# print("cols: ", cols)
# make an array in 2nd dimension with hopSize
frames = as_strided(samples, shape=(int(cols), frameSize), strides = (samples.strides[0] * hopSize, samples.strides[0])).copy()
frames = frames * win
return rfft(frames)
def main():
frameSize = 256
sample_rate, samples = wav.read('./wav/ichi.wav')
print("sample_rate:", sample_rate)
print("num_of_samples:", len(samples))
spectrogram = stft(samples, frameSize)
frequency_map = np.fft.fftfreq(frameSize, 1. / sample_rate)
spectrogram = 20. * np.log10(np.abs(spectrogram)) # amplitude to decibel
# spectrogaram has an extra colum, so slice it
spectrogram = spectrogram[:,:int(np.floor(frameSize/2))]
times, ftaps = np.shape(spectrogram)
print(spectrogram.shape)
plt.figure(figsize=(16, 8))
plt.imshow(np.transpose(spectrogram), origin="lower", aspect="auto", cmap="jet", interpolation="none")
plt.colorbar()
plt.xlabel("time (s)")
plt.ylabel("frequency (hz)")
plt.xlim([0, times-1])
plt.ylim([0, ftaps-1])
xlocs = np.float32(np.linspace(0, times-1, 5))
plt.xticks(xlocs, ["%.02f" % i for i in (xlocs * frameSize / sample_rate)])
ylocs = np.int16(np.floor(np.linspace(0, ftaps-1, 10)))
plt.yticks(ylocs, ["%.02f" % frequency_map[i] for i in ylocs])
plt.show()
plt.clf()
if __name__ == "__main__":
main()
プログラムの詳しい解説は省きますが、記録したオーディオ信号をFFTのタップ数(frameSize=256)の半分ずつ(overlapFac=0.5,128)を移動しながらFFTをかけています。
プログラム上で注意すべき点は音声ファイルをタップ数に分割して2次元配列にしているところと、横軸と縦軸の物理量の算出あたりでしょうか。
違いが出るのか確認するために、今回は、”イチ”、”二”、”サン”と数字を発音したファイルをそれぞれスペクトログラムに変換してみました。その結果がこれです。
”イチ”
.png)
”ニ”
-283a1.png)
"サン"
-44800.png)
結構、特徴が出るものですね。これなら認識できるかな?🤔
( ̄ー ̄)
- 出版社/メーカー: コロナ社
- 発売日: 2018/04/04
- メディア: 単行本
Pythonデータサイエンスハンドブック ―Jupyter、NumPy、pandas、Matplotlib、scikit-learnを使ったデータ分析、機械学習
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/05/26
- メディア: 単行本(ソフトカバー)
")
現場で使える! Python自然言語処理入門 (AI & TECHNOLOGY)
- 出版社/メーカー: 翔泳社
- 発売日: 2020/01/20
- メディア: 単行本(ソフトカバー)
【アフターコロナの世界】私のテレワーク生活スタイル [徒然日記]

■テレワーク■
"打合せはテレカンで"というのはもう当たり前のものとなってきました。最近は一回もF2Fで会ったこともない人ととも、テレカンで何度も打合せをしているうちに、旧知の仲のように思えるようになってくるので不思議です。
■職場の飲み会■
あれだけ頻繁にあった職場の飲み会はすっかり過去のものとなってしまいました。コロナ初期は宅飲みってやつもありましたが、最近はすっかりなくなりました。テレカンでも十分仲間同士のコミュニケーションはとれるってことなんでしょう。
■スーツ■
スーツを着る機会も少なくなりました。テレカンも上半身だけなので、良くて襟付きシャツ、下手するとポロシャツやTシャツです。最近は”資料共有するのに支障が出るといけないのでカメラオフにしてますー”と顔出しなし。ひどい時は寝間着で参加。^^
■外食■
外食は少しするようになってきてました。さすがに気分転換したいので。そのためか、近所のレストランは賑わいを取り戻してきています。ただ、ソーシャルディスタンスのため席数は少ないままですね。
■通勤■
電車はすっかり乗らなくなりました。会社も定期代支給をやめてしまいましたし。通勤がなくなったので、すっかり運動不足となってしまいました。最近は毎日5~6km走るようにしています。
■残業■
もともと残業代がつく立場ではないので、あまり残業時間を気にすることはないのですが、私生活と仕事の切れ目がほとんどなくなってしまったので、際限なく仕事をしてしまうこともしばしばです。
■旅行■
遊びに行くにはまだ早いですが、息子が地方大学に行ったので遠出はします。人混みを避けるため車での移動です。車は便利ですし、まとまった人数だと安いので、コロナ後も旅行は車がメインになりそうです。コロナ前は電車がメインだったのですが。
■アフターコロナの世界■
これが私の最近の生活スタイルなのですが、在宅勤務をされている皆さんも同じではないでしょうか?さて、ここから垣間見えてくるアフターコロナの世界ですが、私の生活スタイルをベースにすると、次のようになりそうです。
・電車の利用は減りそうです。運賃が高くなりそうですね。
・紳士服業界もかなり厳しいですね。スーツも昔のように高くなるのかなぁ。
・郊外のレストランは、コロナが落ち着けば需要は復活するかもしれません。
・都会の居酒屋は厳しいでしょうね。サラリーマン需要が減りますので。
・運動不足から、スポーツ用品の需要は高まるかもしれません。
・意外ですが、車の需要は高まるかもしれません。
・残業を計る基準がなくなるので、雇用形態は変わっていくと思います。
・旅行は車をベースとしたプランがメインになるのかな。
・オフィスの需要は減るので、代わりに貸し会議室やホテルが増えそうですね。
気になるのはイベントですが、コロナが落ち着けばまた復活すると思います。オンラインってやっぱり味気ないですからね。あと2、3年の我慢ですね。
(´・ω・`)
- 出版社/メーカー: 日経BP
- 発売日: 2020/06/02
- メディア: Kindle版
![アフターコロナの日本経済 半年後、1年後、5年後(プレジデント2020年7/31号) [雑誌]](https://m.media-amazon.com/images/I/51n1KdqR5DL._SL160_.jpg "アフターコロナの日本経済 半年後、1年後、5年後(プレジデント2020年7/31号) [雑誌]")
アフターコロナの日本経済 半年後、1年後、5年後(プレジデント2020年7/31号) [雑誌]
- 作者: PRESIDENT 編集部
- 出版社/メーカー: プレジデント社
- 発売日: 2020/07/10
- メディア: Kindle版

これ1冊で先が見通せる!アフターコロナ消費&キャッシュレス最新勢力図
- 出版社/メーカー: 日経BP
- 発売日: 2020/07/02
- メディア: Kindle版
息子、いよいよ一人暮らしを開始する! [4コマ漫画]

カミさんは、息子の生活が気が気でないようで頻繁にメッセージを送っているようなのですが、その返事が意味不明で悩むこともしばしば。私も文章入力するのが面倒でスタンプを返すことが多いのですが、どうやら息子も同じようです。(^_^;)
次に息子が戻ってくるのは夏休み。一ヶ月後くらいです。息子が街に慣れるにはちょうどよい期間になりそうです。 🙂
(^^)
")
オンライン学習でできること、できないこと (新しい学習様式への挑戦)
- 作者: 千葉大学教育学部附属小学校
- 出版社/メーカー: 明治図書出版
- 発売日: 2020/09/10
- メディア: 単行本
")
免疫力を上げる! ハーバード大学式 命の野菜スープ 新型コロナウイルスに勝つ! (TJMOOK)
- 作者: 髙橋 弘
- 出版社/メーカー: 宝島社
- 発売日: 2020/06/18
- メディア: 大型本

- 出版社/メーカー: 主婦の友社
- 発売日: 2018/03/01
- メディア: 単行本(ソフトカバー)
ネオワイズ彗星がいよいよ見頃! [徒然日記]

https://apod.nasa.gov/apod/ap200709.html
7月中旬前は、夜明けまえに見ることができます。ASTROARTSさんのページからの引用です。
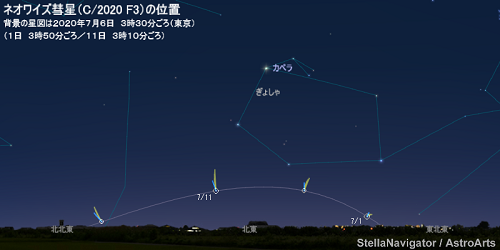
https://www.astroarts.co.jp/article/hl/a/11302_ph200700
今、日本は雨が大変な状況ですので、7月上旬は星空の機会がないかもしれませんが、チャンスがあれば早起きをして東の空を見上げてみてください。
7月中旬以降は、夕暮れになります。この時には天気も一段落していることを願いたいところです。夕焼けの西の空に映えるほうき星は見ものでしょうね。天災続きの日本の厄を、そのほうきで払ってほしいものです。
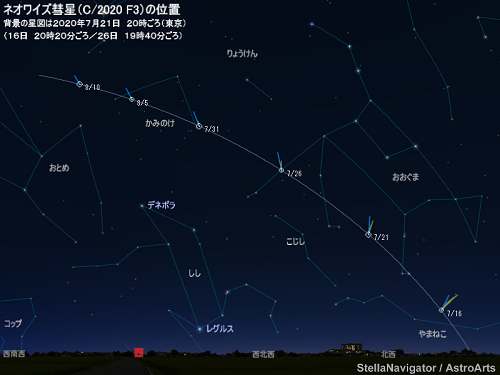
https://www.astroarts.co.jp/article/hl/a/11302_ph200700
数十年に一度のチャンスですので、ぜひ夜明けもしくは夕暮れの夜空を見上げてみてください。私は、久しぶりに天体望遠鏡を引っ張り出してこようと思います!🙂
(^^)/

- 出版社/メーカー: 恒星社厚生閣
- 発売日: 2013/09/14
- メディア: 単行本(ソフトカバー)
![天文ガイド 2020年 8月号 特大号 別添付録付 [雑誌]](https://m.media-amazon.com/images/I/51dJvwIVO5L._SL160_.jpg "天文ガイド 2020年 8月号 特大号 別添付録付 [雑誌]")
天文ガイド 2020年 8月号 特大号 別添付録付 [雑誌]
- 出版社/メーカー: 誠文堂新光社
- 発売日: 2020/07/04
- メディア: 雑誌

- 出版社/メーカー: KADOKAWA
- 発売日: 2020/07/04
- メディア: 雑誌
コロナの最新状況とアフターコロナの時代 [徒然日記]
まず陽性者数ですが、ニュースの通り、ここ最近はかなりの増加傾向です。
.png)
入院治療を必要とする人の数も増えています。
-869d6.png)
この増加はPCR検査人数を増やしているのと関連しているのかもと思い検査人数を確認すると、確かに増えているようです。ここは相関がありそうです。
-c88be.png)
実行再生産数(感染力)も増えています。ここもPCR検査人数と関連しているように見えます。しかし、より実態に近い感染力の数字が出ているといえますので、今までが低すぎました。
-5fe7b.png)
しかし、重症者数については、着実に減っています。
-2221f.png)
死亡者数も同様ですね。日本の医療体制がコロナに対して盤石になりつつあると見ることができますが、一方でコロナが弱毒化している可能性も否定できません。
-2dab2.png)
年齢別の陽性者数を見ると20代~50代が突出しています。いわゆる生産年齢に該当する人たちです。明らかに自粛解除の影響が出ていることが見受けられます。
-d375d.png)
また死亡者も60代~80代に多いのも目を引きます。高齢者の方たちをコロナから遠ざけるための社会的なしくみが必要になってくると思います。
これらの数字から考えられる課題は次の3点になると思います。
(1)高齢者をコロナから遠ざける社会的しくみ
(2)生産年齢層の感染の抑制
(3)海外の変異型コロナの流入阻止 (弱毒化コロナの変異防止)
この課題の解決策は”一極集中の解消”と”入国審査の厳格な運用”になると思います。
”入国審査の厳格な運用”は、来訪者の”出国時のPCR/抗体検査”と”入国時のPCR/抗体検査”の徹底です。これが出来ない国からの入国は認めないくらい厳格な運用をしてほしいものです。
”一極集中の解消”については、インフラの整っている首都圏からお年寄りが動いてもらうのは大変なので、経済力のある生産年齢層に動いてもらうのがてっとり早いと思います。手始めに政府機能を東北や四国あたりに移転してみてはでしょう。地方創生ならびに国内需要も喚起できて一石二鳥です。
今のところ、コロナに対する一番の特効薬は社会的なしくみの変革なので、今こそ政治家の方々の手腕に期待したいところですね。🤔
( ̄ω ̄;)
- 出版社/メーカー: 日経BP
- 発売日: 2020/06/02
- メディア: Kindle版
アフターコロナの日本経済 半年後、1年後、5年後(プレジデント2020年7/31号) [雑誌]
- 作者: PRESIDENT 編集部
- 出版社/メーカー: プレジデント社
- 発売日: 2020/07/10
- メディア: Kindle版
![週刊ダイヤモンド 2020年 7/18号 [雑誌] (アフターコロナの業界総予測)](https://m.media-amazon.com/images/I/51lDMgoCXEL._SL160_.jpg "週刊ダイヤモンド 2020年 7/18号 [雑誌] (アフターコロナの業界総予測)")
週刊ダイヤモンド 2020年 7/18号 [雑誌] (アフターコロナの業界総予測)
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2020/07/13
- メディア: 雑誌
ys_taro さん

-
nice! 35196
記事 1099
テーマ 趣味・カルチャー
プロフィール
Contact Me


