スペクトログラムの学習用データを生成する [AI]
前回、音声ファイルからスペクトログラムを生成しました。Neural Network Console で学習させるためには、学習用データを生成する必要がありますが、たくさんのデータを記録するのはめんどくさい。
そこで、既存データを加工して学習用データを生成したいと思います。このとき、生成するデータは、次の2つの要因を考慮する必要があります。
(1)音声が入ってくるタイミングはバラバラ
(2)キャプチャされる音声のレベルは一定でない
これらのデータを生成するには、得られたスペクトログラムを左右にランダムに降り、スペクトルのレベル(ゲイン)をランダムに変化させたデータを生成するのがよさそうです。
■ スペクトログラムのデータを左右に降る
スペクトログラムの信号が現れる位置と信号がなくなる位置を検出し移動できる量を特定します。左右に位置はランダムにずらします。そのときに、ずらした分のノイズは入れ替えます。
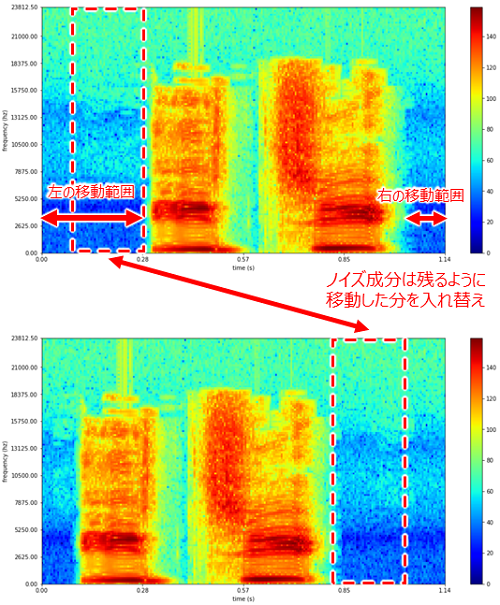
■ スペクトルのゲインを変化させる
スペクトルのゲインは、一旦ここでは最大値が255になるか、最小値はデータの最大値の2/3となるようにします。実際の運用では、最小値の値を使用するマイクにあわせたほうがいいでしょう。
■ スペクトログラムの data augumentation のPythonスケッチを書く
以上、2点に留意して検証用のPythonスケッチを作ってみました。まだお試しなのでパラメータは直打ちです。
少し工夫した点は、開始点 (up_trigger)、終了点(down_trigger)の判定に前後3ラインの出力の平均を使っているところです。これにより精度よく開始点と終了点を判別できるようになりました。
試しに、”イチ”、”二”、”サン”の音声データを加工してみました。
”イチ”
-a90de.png)
”二”
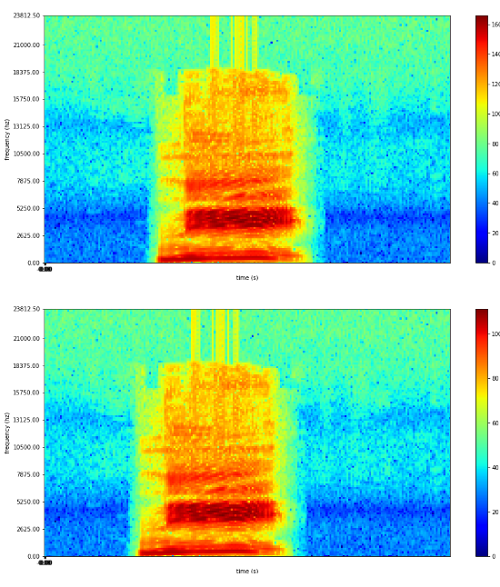
”サン”
-5ef38.png)
なかなかいい感じですね。ただ実際には、マイクのノイズの下限は一定になるので、ノイズのレベルもゲインを下げているのは現実的ではありません。それについては、実際にマイクの特性を見てから考えたいと思います。
次は、このデータを使って畳み込みニューラルネットワークで、"イチ"、"二"、"サン"を判定できるかチャレンジしてみたいと思います!
(^^)/~
")
")

そこで、既存データを加工して学習用データを生成したいと思います。このとき、生成するデータは、次の2つの要因を考慮する必要があります。
(1)音声が入ってくるタイミングはバラバラ
(2)キャプチャされる音声のレベルは一定でない
これらのデータを生成するには、得られたスペクトログラムを左右にランダムに降り、スペクトルのレベル(ゲイン)をランダムに変化させたデータを生成するのがよさそうです。
■ スペクトログラムのデータを左右に降る
スペクトログラムの信号が現れる位置と信号がなくなる位置を検出し移動できる量を特定します。左右に位置はランダムにずらします。そのときに、ずらした分のノイズは入れ替えます。
■ スペクトルのゲインを変化させる
スペクトルのゲインは、一旦ここでは最大値が255になるか、最小値はデータの最大値の2/3となるようにします。実際の運用では、最小値の値を使用するマイクにあわせたほうがいいでしょう。
■ スペクトログラムの data augumentation のPythonスケッチを書く
以上、2点に留意して検証用のPythonスケッチを作ってみました。まだお試しなのでパラメータは直打ちです。
import numpy as np
import scipy.io.wavfile as wav
from matplotlib import pyplot as plt
from numpy.lib import stride_tricks
from numpy.lib.stride_tricks import as_strided
from numpy.fft import rfft
times = 0
ftaps = 0
frameSize = 0
""" short time fourier transform of audio signal """
def stft(samples, frameSize, overlapFac = 0.5, window = np.hanning):
win = window(frameSize)
hopSize = int(frameSize - np.floor(overlapFac * frameSize))
# cols for windowing
cols = np.floor(len(samples) / hopSize) - 1
# print("cols: ", cols)
# make an array in 2nd dimension with hopSize
frames = as_strided(samples, shape=(int(cols), frameSize), strides = (samples.strides[0] * hopSize, samples.strides[0])).copy()
frames = frames * win
return rfft(frames)
def augmentator(spectrogram):
spectro_mean = np.mean(spectrogram, axis=1)
threshold = np.mean(spectro_mean)
threshold = np.mean(spectro_mean[spectro_mean <= threshold]) # pick up only noise signals
print("threshold: ", threshold)
up_trigger = 0
down_trigger = 0
for i in range(3, spectro_mean.shape[0]-3):
if ((np.mean(spectro_mean[i:i+2]) > threshold) and (np.mean(spectro_mean[i-3:i-1]) <= threshold) and (up_trigger == 0)):
up_trigger = i
if ((np.mean(spectro_mean[i:i+2]) <= threshold) and (np.mean(spectro_mean[i-3:i-1]) > threshold)):
down_trigger = i
print("up_trigger : ", up_trigger)
print("down_trigger: ", down_trigger)
move = -10 #if the shift is left, the value is minus, the shift is right, tha value is plus
spectrogram_result = spectrogram.copy()
spectrogram_body = spectrogram[up_trigger:down_trigger, :]
if (move < 0):
spectrogram_noise = spectrogram[up_trigger+move:up_trigger,:]
spectrogram_result[up_trigger+move:down_trigger+move,:] = spectrogram_body
spectrogram_result[down_trigger+move:down_trigger,:] = spectrogram_noise
elif (move > 0):
spectrogram_noise = spectrogram[down_trigger:down_trigger+move,:]
spectrogram_result[up_trigger+move:down_trigger+move,:] = spectrogram_body
spectrogram_result[up_trigger:up_trigger+move,:] = spectrogram_noise
gain = 255 / np.max(spectrogram) # maximum gain
# gain = 0.67 # minmum gain
return spectrogram_result * gain
def plot_spectrogram(spectrogram, time_axis, freq_axis, time_interval, frequency_map):
plt.figure(figsize=(16, 8))
plt.imshow(np.transpose(spectrogram), origin="lower", aspect="auto", cmap="jet", interpolation="none")
plt.colorbar()
plt.xlabel("time (s)")
plt.ylabel("frequency (hz)")
plt.xlim([0, time_axis-1])
plt.ylim([0, freq_axis-1])
xlocs = np.float32(np.linspace(0, times-1, 5))
plt.xticks(xlocs, ["%.02f" % i for i in (xlocs * time_interval)])
ylocs = np.int16(np.floor(np.linspace(0, freq_axis-1, 10)))
plt.yticks(ylocs, ["%.02f" % frequency_map[i] for i in ylocs])
plt.show()
def main():
frameSize = 256
sample_rate, samples = wav.read('./wav/ni1.wav')
print("sample_rate:", sample_rate)
print("num_of_samples:", len(samples))
spectrogram = stft(samples, frameSize)
frequency_map = np.fft.fftfreq(frameSize, 1. / sample_rate)
spectrogram = 20. * np.log10(np.abs(spectrogram)) # amplitude to decibel
# spectrogaram has an extra colum, so slice it
spectrogram = spectrogram[:,:int(np.floor(frameSize/2))]
time_dim, freq_dim = np.shape(spectrogram)
print(spectrogram.shape)
spectrogram -= np.min(spectrogram)
max_spectro = np.max(spectrogram) # normalize
print("MAX: ", max_spectro)
time_interval = frameSize / sample_rate
plot_spectrogram(spectrogram, time_dim, freq_dim, time_interval, frequency_map)
spectrogram = augmentator(spectrogram)
plot_spectrogram(spectrogram, time_dim, freq_dim, time_interval, frequency_map)
if __name__ == "__main__":
main()
少し工夫した点は、開始点 (up_trigger)、終了点(down_trigger)の判定に前後3ラインの出力の平均を使っているところです。これにより精度よく開始点と終了点を判別できるようになりました。
試しに、”イチ”、”二”、”サン”の音声データを加工してみました。
”イチ”
”二”
”サン”
なかなかいい感じですね。ただ実際には、マイクのノイズの下限は一定になるので、ノイズのレベルもゲインを下げているのは現実的ではありません。それについては、実際にマイクの特性を見てから考えたいと思います。
次は、このデータを使って畳み込みニューラルネットワークで、"イチ"、"二"、"サン"を判定できるかチャレンジしてみたいと思います!
(^^)/~
NumPy&SciPy数値計算実装ハンドブック (Pythonライブラリ定番セレクション)
- 出版社/メーカー: 秀和システム
- 発売日: 2019/08/23
- メディア: 単行本
現場で使える! Python科学技術計算入門 NumPy/SymPy/SciPy/pandasによる数値計算・データ処理手法 (AI & TECHNOLOGY)
- 作者: かくあき
- 出版社/メーカー: 翔泳社
- 発売日: 2020/05/19
- メディア: 単行本(ソフトカバー)
Pythonデータサイエンスハンドブック ―Jupyter、NumPy、pandas、Matplotlib、scikit-learnを使ったデータ分析、機械学習
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/05/26
- メディア: 単行本(ソフトカバー)
ys_taro さん

-
nice! 35196
記事 1099
テーマ 趣味・カルチャー
プロフィール
Contact Me


