スペクトログラムの学習用データの生成を自動化する [AI]
前回と同じくデータは、”イチ”、”二”、”サン”の3つ。それに無音も認識が必要なので無音のノイズデータの4点です。学習用の画像データは32x32の大きさにしました。結果から出してしまいますが、次のようなデータが生成されました。
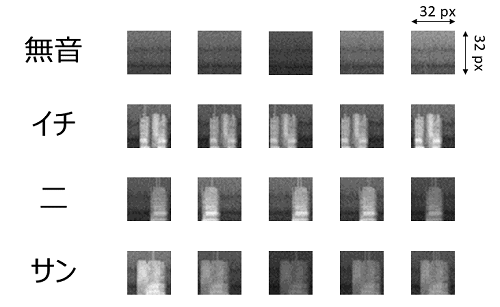
Python のスケッチを次にあげておきます。見通しをよくするために幾つか関数に分離をしていますが、前回のアルゴリズムをそのまま踏襲しています。追加した処理は、次の3点です。
(1) 無音時のノイズ処理(スペクトラムの範囲を決められない為)
(2) ランダムにシフト量とゲイン量を算出する処理
(3) スペクトラムをリサイズして画像として保存する処理
import numpy as np
import cv2 as cv
import random
import os
import scipy.io.wavfile as wav
from matplotlib import pyplot as plt
from numpy.lib import stride_tricks
from numpy.lib.stride_tricks import as_strided
from numpy.fft import rfft
""" short time fourier transform of audio signal """
def stft(samples, frameSize, overlapFac = 0.5, window = np.hanning):
win = window(frameSize)
hopSize = int(frameSize - np.floor(overlapFac * frameSize))
# cols for windowing
cols = np.floor(len(samples) / hopSize) - 1
# print("cols: ", cols)
# make an array in 2nd dimension with hopSize
frames = as_strided(samples, shape=(int(cols), frameSize), strides = (samples.strides[0] * hopSize, samples.strides[0])).copy()
frames = frames * win
return rfft(frames)
def spectrogram_detector(spectrogram):
spectro_mean = np.mean(spectrogram, axis=1)
threshold = np.ceil(np.mean(spectro_mean))
threshold = np.ceil(np.mean(spectro_mean[spectro_mean <= threshold])) # pick up only noise signals
print("threshold: ", threshold)
offset = 5
up_trigger = 0
down_trigger = 0
for i in range(offset, spectro_mean.shape[0]-offset):
cur_floor = int(np.mean(spectro_mean[i:i+offset-1]))
pre_floor = int(np.mean(spectro_mean[i-offset:i-1]))
if ((cur_floor > threshold) and (pre_floor <= threshold) and (up_trigger == 0)):
up_trigger = i
if ((cur_floor <= threshold) and (pre_floor > threshold)):
down_trigger = i
print("up_trigger : ", up_trigger)
print("down_trigger: ", down_trigger)
return up_trigger, down_trigger
def augmentator(spectrogram, left, right, signal):
axis_max = spectrogram.shape[0]
if (signal == 0): # in case of zero1.wav
left = random.randint(0, np.floor(axis_max/2))
right = random.randint(np.ceil(axis_max/2), axis_max-1)
left_or_right = random.randint(0,1)
if (left_or_right > 0): # 1 is right, 0 is left
move = random.randint(right, axis_max-1)
move = move - right
else:
move = random.randint(0,left)
move = -move
print("move: ", move)
spectrogram_result = spectrogram.copy()
spectrogram_body = spectrogram[left:right, :] # extract spectoram data
#if the shift is left, the value is minus, the shift is right, tha value is plus
if (move < 0):
spectrogram_noise = spectrogram[left+move:left,:]
spectrogram_result[left+move:right+move,:] = spectrogram_body
spectrogram_result[right+move:right,:] = spectrogram_noise
elif (move > 0):
spectrogram_noise = spectrogram[right:right+move,:]
spectrogram_result[left+move:right+move,:] = spectrogram_body
spectrogram_result[left:left+move,:] = spectrogram_noise
max_gain = 255 / np.max(spectrogram) # maximum gain
gain = random.uniform(0.67, max_gain)
print("gain: ", gain)
return spectrogram_result * gain
def plot_spectrogram(spectrogram, time_axis, freq_axis, time_interval, frequency_map):
plt.figure(figsize=(16, 8))
plt.imshow(np.transpose(spectrogram), origin="lower", aspect="auto", cmap="jet", interpolation="none")
plt.colorbar()
plt.xlabel("time (s)")
plt.ylabel("frequency (hz)")
plt.xlim([0, time_axis-1])
plt.ylim([0, freq_axis-1])
xlocs = np.float32(np.linspace(0, time_axis-1, 5))
plt.xticks(xlocs, ["%.02f" % i for i in (xlocs * time_interval)])
ylocs = np.int16(np.floor(np.linspace(0, freq_axis-1, 10)))
plt.yticks(ylocs, ["%.02f" % frequency_map[i] for i in ylocs])
plt.show()
def gen_spectrogram(wavfile, frameSize):
sample_rate, samples = wav.read(wavfile)
print("sample_rate:", sample_rate)
print("num_of_samples:", len(samples))
spectrogram = stft(samples, frameSize)
frequency_map = np.fft.fftfreq(frameSize, 1. / sample_rate)
spectrogram = 20. * np.log10(np.abs(spectrogram)) # amplitude to decibel
# spectrogaram has an extra colum, so slice it
spectrogram = spectrogram[:,:int(np.floor(frameSize/2))]
spectrogram -= np.min(spectrogram) # normalize
return spectrogram, sample_rate, frequency_map
def main():
frameSize = 256
output_img_size = 32
num_of_augdata = 5
wavfiles = ['./wav/zero1.wav', './wav/ichi1.wav', './wav/ni1.wav', './wav/san1.wav']
for i in range(len(wavfiles)):
print(wavfiles[i])
spectrogram, sample_rate, frequency_map = gen_spectrogram(wavfiles[i], frameSize)
time_dim, freq_dim = np.shape(spectrogram)
time_interval = frameSize / sample_rate
plot_spectrogram(spectrogram, time_dim, freq_dim, time_interval, frequency_map)
# detect the range of spectrogram signal
left, right = spectrogram_detector(spectrogram)
data_dir = "./" + str(i)
if not os.path.exists(data_dir):
os.mkdir(data_dir)
for n in range(num_of_augdata):
# spectrogram data augmentator
spectro_aug = augmentator(spectrogram, left, right, i)
# plot_spectrogram(spectro_aug, time_dim, freq_dim, time_interval, frequency_map)
spectro_aug.astype(np.uint8)
spectro_img = cv.resize(spectro_aug, (output_img_size, output_img_size))
spectro_img = np.rot90(spectro_img)
data_path = data_dir + "/" + str(n) + ".bmp"
cv.imwrite(data_path, spectro_img)
if __name__ == "__main__":
main()
おそらく実機では、マイクのノイズやゲイン量が大きく影響するので作り直しになると思いますが、このスケッチそのものはパラメータなどを変更することで流用できそうです。
(^^)/~

- 出版社/メーカー: コロナ社
- 発売日: 2018/04/04
- メディア: 単行本

データサイエンス教本 Pythonで学ぶ統計分析・パターン認識・深層学習・信号処理・時系列データ分析
- 出版社/メーカー: オーム社
- 発売日: 2019/01/18
- メディア: Kindle版

Pythonデータサイエンスハンドブック ―Jupyter、NumPy、pandas、Matplotlib、scikit-learnを使ったデータ分析、機械学習
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/05/26
- メディア: 単行本(ソフトカバー)
スペクトログラムの学習用データを生成する [AI]
そこで、既存データを加工して学習用データを生成したいと思います。このとき、生成するデータは、次の2つの要因を考慮する必要があります。
(1)音声が入ってくるタイミングはバラバラ
(2)キャプチャされる音声のレベルは一定でない
これらのデータを生成するには、得られたスペクトログラムを左右にランダムに降り、スペクトルのレベル(ゲイン)をランダムに変化させたデータを生成するのがよさそうです。
■ スペクトログラムのデータを左右に降る
スペクトログラムの信号が現れる位置と信号がなくなる位置を検出し移動できる量を特定します。左右に位置はランダムにずらします。そのときに、ずらした分のノイズは入れ替えます。
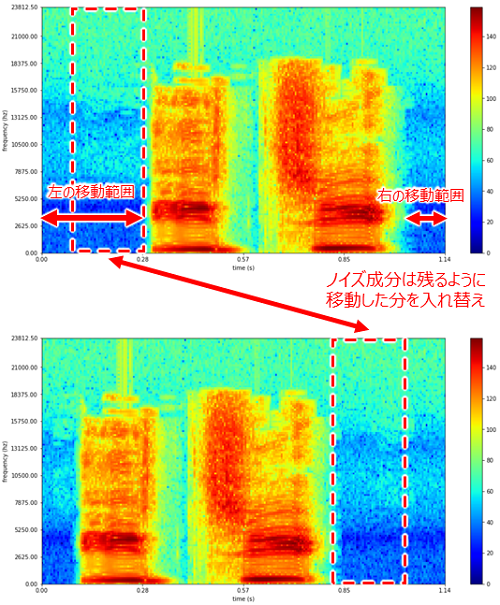
■ スペクトルのゲインを変化させる
スペクトルのゲインは、一旦ここでは最大値が255になるか、最小値はデータの最大値の2/3となるようにします。実際の運用では、最小値の値を使用するマイクにあわせたほうがいいでしょう。
■ スペクトログラムの data augumentation のPythonスケッチを書く
以上、2点に留意して検証用のPythonスケッチを作ってみました。まだお試しなのでパラメータは直打ちです。
import numpy as np
import scipy.io.wavfile as wav
from matplotlib import pyplot as plt
from numpy.lib import stride_tricks
from numpy.lib.stride_tricks import as_strided
from numpy.fft import rfft
times = 0
ftaps = 0
frameSize = 0
""" short time fourier transform of audio signal """
def stft(samples, frameSize, overlapFac = 0.5, window = np.hanning):
win = window(frameSize)
hopSize = int(frameSize - np.floor(overlapFac * frameSize))
# cols for windowing
cols = np.floor(len(samples) / hopSize) - 1
# print("cols: ", cols)
# make an array in 2nd dimension with hopSize
frames = as_strided(samples, shape=(int(cols), frameSize), strides = (samples.strides[0] * hopSize, samples.strides[0])).copy()
frames = frames * win
return rfft(frames)
def augmentator(spectrogram):
spectro_mean = np.mean(spectrogram, axis=1)
threshold = np.mean(spectro_mean)
threshold = np.mean(spectro_mean[spectro_mean <= threshold]) # pick up only noise signals
print("threshold: ", threshold)
up_trigger = 0
down_trigger = 0
for i in range(3, spectro_mean.shape[0]-3):
if ((np.mean(spectro_mean[i:i+2]) > threshold) and (np.mean(spectro_mean[i-3:i-1]) <= threshold) and (up_trigger == 0)):
up_trigger = i
if ((np.mean(spectro_mean[i:i+2]) <= threshold) and (np.mean(spectro_mean[i-3:i-1]) > threshold)):
down_trigger = i
print("up_trigger : ", up_trigger)
print("down_trigger: ", down_trigger)
move = -10 #if the shift is left, the value is minus, the shift is right, tha value is plus
spectrogram_result = spectrogram.copy()
spectrogram_body = spectrogram[up_trigger:down_trigger, :]
if (move < 0):
spectrogram_noise = spectrogram[up_trigger+move:up_trigger,:]
spectrogram_result[up_trigger+move:down_trigger+move,:] = spectrogram_body
spectrogram_result[down_trigger+move:down_trigger,:] = spectrogram_noise
elif (move > 0):
spectrogram_noise = spectrogram[down_trigger:down_trigger+move,:]
spectrogram_result[up_trigger+move:down_trigger+move,:] = spectrogram_body
spectrogram_result[up_trigger:up_trigger+move,:] = spectrogram_noise
gain = 255 / np.max(spectrogram) # maximum gain
# gain = 0.67 # minmum gain
return spectrogram_result * gain
def plot_spectrogram(spectrogram, time_axis, freq_axis, time_interval, frequency_map):
plt.figure(figsize=(16, 8))
plt.imshow(np.transpose(spectrogram), origin="lower", aspect="auto", cmap="jet", interpolation="none")
plt.colorbar()
plt.xlabel("time (s)")
plt.ylabel("frequency (hz)")
plt.xlim([0, time_axis-1])
plt.ylim([0, freq_axis-1])
xlocs = np.float32(np.linspace(0, times-1, 5))
plt.xticks(xlocs, ["%.02f" % i for i in (xlocs * time_interval)])
ylocs = np.int16(np.floor(np.linspace(0, freq_axis-1, 10)))
plt.yticks(ylocs, ["%.02f" % frequency_map[i] for i in ylocs])
plt.show()
def main():
frameSize = 256
sample_rate, samples = wav.read('./wav/ni1.wav')
print("sample_rate:", sample_rate)
print("num_of_samples:", len(samples))
spectrogram = stft(samples, frameSize)
frequency_map = np.fft.fftfreq(frameSize, 1. / sample_rate)
spectrogram = 20. * np.log10(np.abs(spectrogram)) # amplitude to decibel
# spectrogaram has an extra colum, so slice it
spectrogram = spectrogram[:,:int(np.floor(frameSize/2))]
time_dim, freq_dim = np.shape(spectrogram)
print(spectrogram.shape)
spectrogram -= np.min(spectrogram)
max_spectro = np.max(spectrogram) # normalize
print("MAX: ", max_spectro)
time_interval = frameSize / sample_rate
plot_spectrogram(spectrogram, time_dim, freq_dim, time_interval, frequency_map)
spectrogram = augmentator(spectrogram)
plot_spectrogram(spectrogram, time_dim, freq_dim, time_interval, frequency_map)
if __name__ == "__main__":
main()
少し工夫した点は、開始点 (up_trigger)、終了点(down_trigger)の判定に前後3ラインの出力の平均を使っているところです。これにより精度よく開始点と終了点を判別できるようになりました。
試しに、”イチ”、”二”、”サン”の音声データを加工してみました。
”イチ”
-a90de.png)
”二”
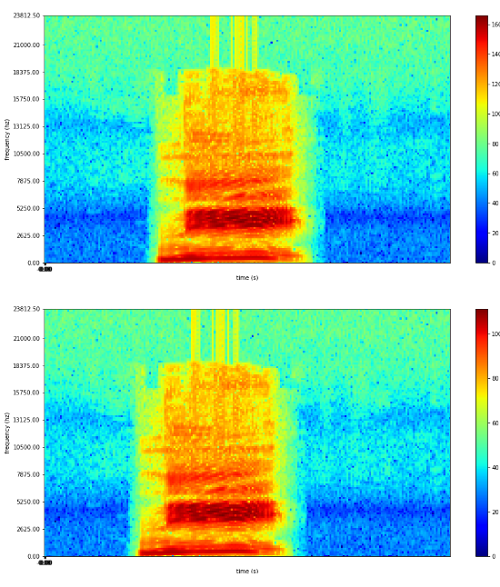
”サン”
-5ef38.png)
なかなかいい感じですね。ただ実際には、マイクのノイズの下限は一定になるので、ノイズのレベルもゲインを下げているのは現実的ではありません。それについては、実際にマイクの特性を見てから考えたいと思います。
次は、このデータを使って畳み込みニューラルネットワークで、"イチ"、"二"、"サン"を判定できるかチャレンジしてみたいと思います!
(^^)/~
")
NumPy&SciPy数値計算実装ハンドブック (Pythonライブラリ定番セレクション)
- 出版社/メーカー: 秀和システム
- 発売日: 2019/08/23
- メディア: 単行本
")
現場で使える! Python科学技術計算入門 NumPy/SymPy/SciPy/pandasによる数値計算・データ処理手法 (AI & TECHNOLOGY)
- 作者: かくあき
- 出版社/メーカー: 翔泳社
- 発売日: 2020/05/19
- メディア: 単行本(ソフトカバー)
Pythonデータサイエンスハンドブック ―Jupyter、NumPy、pandas、Matplotlib、scikit-learnを使ったデータ分析、機械学習
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/05/26
- メディア: 単行本(ソフトカバー)
Python で音声ファイルからスペクトログラムを生成してみた [AI]
その前処理として、Python を使って音声ファイルからスペクトログラムを生成するプログラムを作ってみました。
import numpy as np
import scipy.io.wavfile as wav
from matplotlib import pyplot as plt
from numpy.lib import stride_tricks
from numpy.lib.stride_tricks import as_strided
from numpy.fft import rfft
""" short time fourier transform """
def stft(samples, frameSize, overlapFac = 0.5, window = np.hanning):
win = window(frameSize)
hopSize = int(frameSize - np.floor(overlapFac * frameSize))
# cols for windowing
cols = np.floor(len(samples) / hopSize) - 1
# print("cols: ", cols)
# make an array in 2nd dimension with hopSize
frames = as_strided(samples, shape=(int(cols), frameSize), strides = (samples.strides[0] * hopSize, samples.strides[0])).copy()
frames = frames * win
return rfft(frames)
def main():
frameSize = 256
sample_rate, samples = wav.read('./wav/ichi.wav')
print("sample_rate:", sample_rate)
print("num_of_samples:", len(samples))
spectrogram = stft(samples, frameSize)
frequency_map = np.fft.fftfreq(frameSize, 1. / sample_rate)
spectrogram = 20. * np.log10(np.abs(spectrogram)) # amplitude to decibel
# spectrogaram has an extra colum, so slice it
spectrogram = spectrogram[:,:int(np.floor(frameSize/2))]
times, ftaps = np.shape(spectrogram)
print(spectrogram.shape)
plt.figure(figsize=(16, 8))
plt.imshow(np.transpose(spectrogram), origin="lower", aspect="auto", cmap="jet", interpolation="none")
plt.colorbar()
plt.xlabel("time (s)")
plt.ylabel("frequency (hz)")
plt.xlim([0, times-1])
plt.ylim([0, ftaps-1])
xlocs = np.float32(np.linspace(0, times-1, 5))
plt.xticks(xlocs, ["%.02f" % i for i in (xlocs * frameSize / sample_rate)])
ylocs = np.int16(np.floor(np.linspace(0, ftaps-1, 10)))
plt.yticks(ylocs, ["%.02f" % frequency_map[i] for i in ylocs])
plt.show()
plt.clf()
if __name__ == "__main__":
main()
プログラムの詳しい解説は省きますが、記録したオーディオ信号をFFTのタップ数(frameSize=256)の半分ずつ(overlapFac=0.5,128)を移動しながらFFTをかけています。
プログラム上で注意すべき点は音声ファイルをタップ数に分割して2次元配列にしているところと、横軸と縦軸の物理量の算出あたりでしょうか。
違いが出るのか確認するために、今回は、”イチ”、”二”、”サン”と数字を発音したファイルをそれぞれスペクトログラムに変換してみました。その結果がこれです。
”イチ”
.png)
”ニ”
-283a1.png)
"サン"
-44800.png)
結構、特徴が出るものですね。これなら認識できるかな?🤔
( ̄ー ̄)
- 出版社/メーカー: コロナ社
- 発売日: 2018/04/04
- メディア: 単行本
Pythonデータサイエンスハンドブック ―Jupyter、NumPy、pandas、Matplotlib、scikit-learnを使ったデータ分析、機械学習
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/05/26
- メディア: 単行本(ソフトカバー)
")
現場で使える! Python自然言語処理入門 (AI & TECHNOLOGY)
- 出版社/メーカー: 翔泳社
- 発売日: 2020/01/20
- メディア: 単行本(ソフトカバー)
【Neural Network Console】ついにLSTMにたどり着くの巻 [AI]
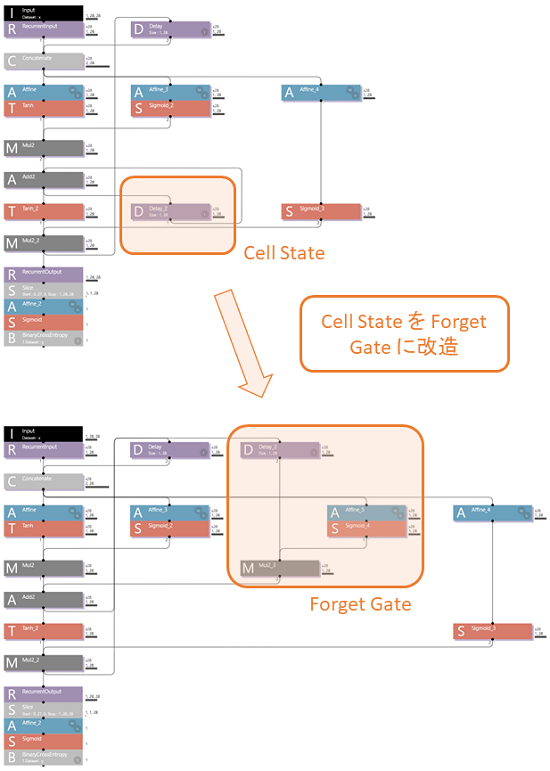
Cell State の役割を覚えているでしょうか?Cell State は過去の出来事を認識結果に反映させるため、加算器(Add2)に出力を加算していく役割をもっていました。
しかし、Cell State は相関の低い結果も加算してしまいます。それを Forget Gate に作り変えて、相関の低いな出力を加算させないようにします。
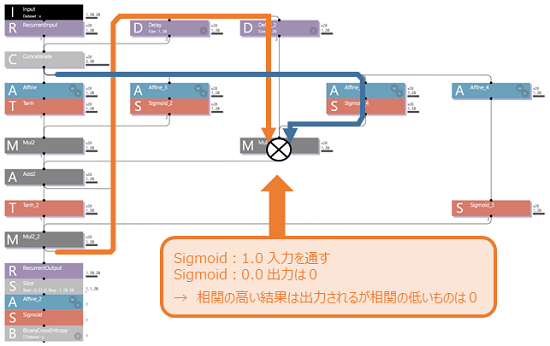
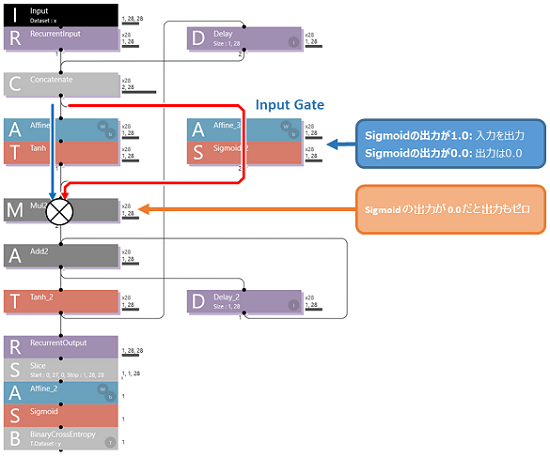
この図のように、Forget Gate は Sigmoid がスイッチの役割になって、相関の低い結果の場合は0を出力するため加算器(Add2)に出力が蓄積されません。
では、学習をさせてみましょう。
-15b28.png)
収束しました。それでは結果はどうなったでしょうか。
-5363d.png)
今まででギリ一番よい結果が出てきました。例によって効果がよく分からないので、最終段をコンボリューションにして、画像で効果を確認してみましょう。
-57eb0.png)
学習結果は相変わらずよいですね。
-670eb.png)
さて気になる結果は?
-ba6ac.png)
おお、かなり良い感じです。相関の高い出力だけが得られているようです。LSTMの効果がこれでようやく分かって来ました。
次はいよいよ SPRESENSE で動かしてみようかなぁ…でも何を認識させよう?🤔
(。-`ω´-) ナヤム…

ソニー開発のNeural Network Console入門【増補改訂・クラウド対応版】--数式なし、コーディングなしのディープラーニング
- 出版社/メーカー: リックテレコム
- 発売日: 2018/11/14
- メディア: 単行本(ソフトカバー)
")
- 作者: 良一, 柴田
- 出版社/メーカー: 工学社
- 発売日: 2019/08/01
- メディア: 単行本

医療AIとディープラーニングシリーズ 2020-2021年版 標準 医用画像のためのディープラーニング-入門編-
- 出版社/メーカー: オーム社
- 発売日: 2020/04/24
- メディア: Kindle版
【Neural Network Console】まだ続くよLSTM、さらに OutputGate を追加してみた [AI]
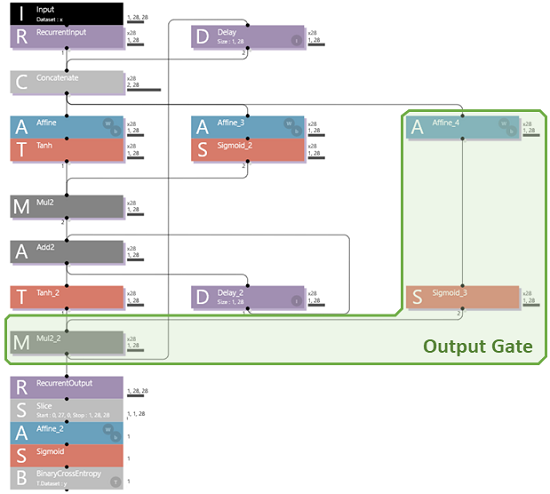
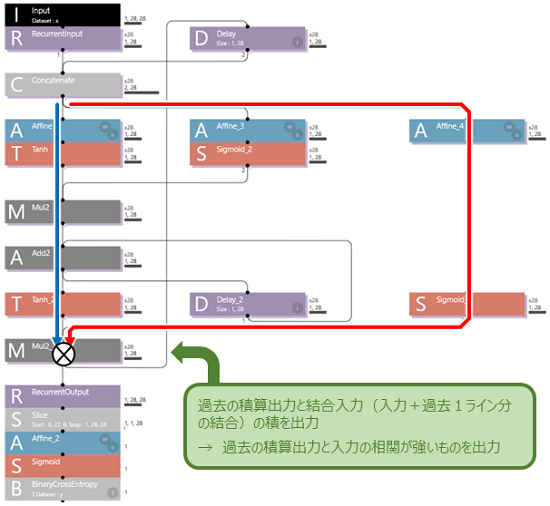
"Output Gate" は、Sigmoidでゲーティングされた”結合入力"の迂回路と"積算出力"との積になっています。これによって過去の"積算出力"と"結合入力"の相関の強い結果が出力されます。
その結果は次のラインに渡され、入力データと直前の結果をあわせることにより、それ以降の層、積算層、”Output Gate" は、より精度の高い結果が得られるようになることが期待されます。
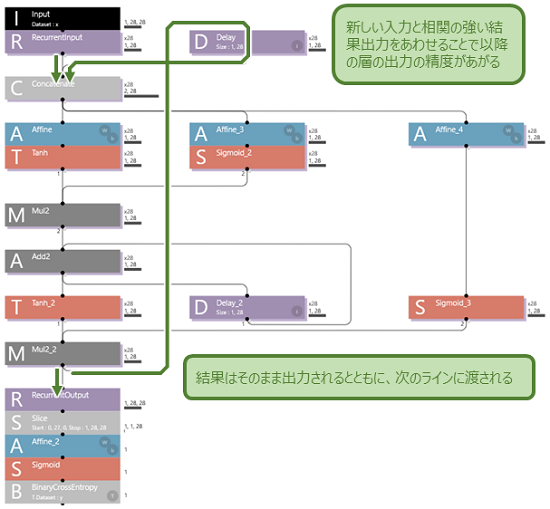
ということで学習をさせました。
.png)
評価結果はというと、、、
-b422f.png)
だいたい96% であまり変わらない…どころか、若干悪化しています。う~ん、これでは良いのかどうなのかよく分からないですね。
ということで例によって最終段を Convolution 層に変えて各時間軸での出力を画像化してみたいと思います。
学習結果は収束しました。
-5218a.png)
結果はこのようになりました。
-1c3b0.png)
改善具合は明らかですね。各時間軸で入力をうまく選別し、より相関の強い出力だけを出力できるようになっているようです。
次は、いよいよLSTM完結編です!😉
( ̄ー ̄)
ソニー開発のNeural Network Console入門【増補改訂・クラウド対応版】--数式なし、コーディングなしのディープラーニング
- 出版社/メーカー: リックテレコム
- 発売日: 2018/11/14
- メディア: 単行本(ソフトカバー)
- 作者: 良一, 柴田
- 出版社/メーカー: 工学社
- 発売日: 2019/08/01
- メディア: 単行本
医療AIとディープラーニングシリーズ 2020-2021年版 標準 医用画像のためのディープラーニング-入門編-
- 出版社/メーカー: オーム社
- 発売日: 2020/04/24
- メディア: Kindle版
【Neural Network Console】LSTMを理解するため、さらに InputGate を追加してみた! [AI]
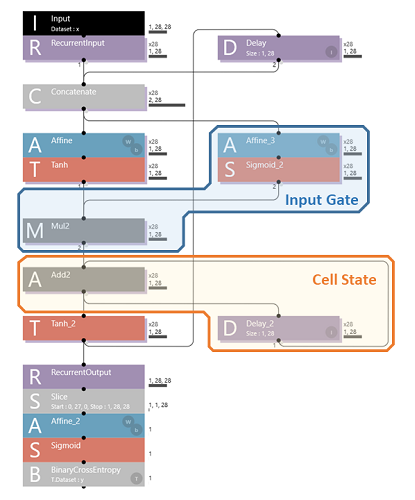
Input Gate は、入力を選択的に取り込む役割を担います。これによって、Cell State が相関度の低い入力でも書き換わってしまうのを防ぐことができます。
学習結果は収束しました。
-48d71.png)
結果を見てみましょう。
-f592d.png)
認識率は 96% で前回とあまり変化はありません。どのような改善効果があったのか良くわからないので、前回と同じく、各時間軸での結果を画像化してみました。例によって最終段を コンボリューションレイヤーに置き換えます。
-063fe.png)
学習結果は収束しました。
-d1ed9.png)
それでは結果を見てみます。
-a929c.png)
前回に比べると、それらしい輪郭が出ています。入力を選択的に取り込んだ結果でしょう。こうやって、一つ一つ動かしてみるとそれぞれのレイヤーの作用がよく分かるのでいいですね!😃
(^^)
ソニー開発のNeural Network Console入門【増補改訂・クラウド対応版】--数式なし、コーディングなしのディープラーニング
- 出版社/メーカー: リックテレコム
- 発売日: 2018/11/14
- メディア: 単行本(ソフトカバー)
- 作者: 良一, 柴田
- 出版社/メーカー: 工学社
- 発売日: 2019/08/01
- メディア: 単行本
医療AIとディープラーニングシリーズ 2020-2021年版 標準 医用画像のためのディープラーニング-入門編-
- 出版社/メーカー: オーム社
- 発売日: 2020/04/24
- メディア: Kindle版
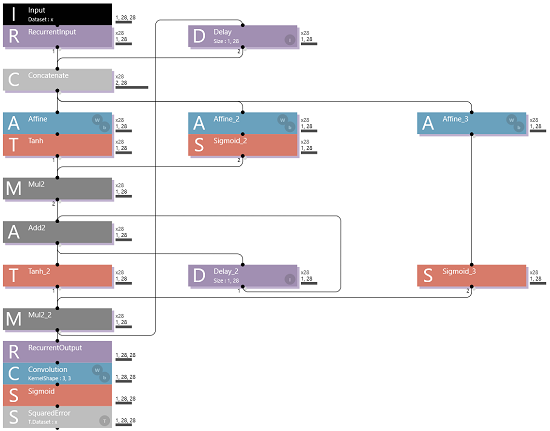
【Neural Network Console】LSTMを理解するため Elman_net に Cell State を追加してみた [AI]
ソニー小林師匠によると、”Cell State” は「過去の出力を足しながら保持し、遠い過去の記憶の消失を防ぐ」役割をもっており各時間軸の出力を加算していくレイヤーです。
で早速、見よう見真似でネットワークを作ってみたのですが、エラーが出てしまいました。
.png)
いろいろと試行錯誤してみたところ、新しく追加した "Delay_2" の”Size”を (1, 28) と指定することで、解決しました。
-44ecc.png)
さて、このネットワークを学習させてみます。
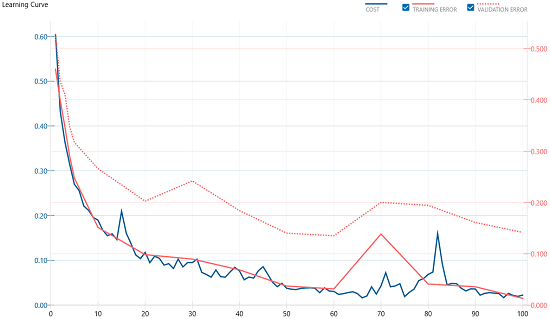
うまく収束しました。評価結果を確認します。
-989bd.png)
認識率は 96% になりました。前回は 93% だったので 3% 向上しました。
前回と同じように、このネットワークの各時間軸の出力結果を画像で出力してみたいと思います。次のようなネットワークを作りました。
-649f2.png)
学習をさせるとうまく収束しました。
-b8183.png)
結果を見てみましょう。
-8834b.png)
前回と違って数字が崩れています。これは加算レイヤーに各時間軸の学習結果が蓄積したためだと思われます。画像をよく見ると、推論方向となる縦に白が多いところは、結果も白くなっていますので、加算レイヤーが大きく影響していることが見受けられます。
今回の実験では、加算レイヤー(Cell State)を追加すると各時間軸の結果に大きく影響することがわかりました
まぁ、画像をスリットで見せられて、最終的に ”これなんだ?” という予測の仕方なので、当然の結果と言えるでしょう。やはりLSTMを扱うには音などの時系列データを使う方がわかりやすいのかなぁ。もうちょっと進め方考えるか…🤨
(´・ω・`)
ソニー開発のNeural Network Console入門【増補改訂・クラウド対応版】--数式なし、コーディングなしのディープラーニング
- 出版社/メーカー: リックテレコム
- 発売日: 2018/11/14
- メディア: 単行本(ソフトカバー)
- 作者: 良一, 柴田
- 出版社/メーカー: 工学社
- 発売日: 2019/08/01
- メディア: 単行本
")
詳解ディープラーニング 第2版 ~TensorFlow/Keras・PyTorchによる時系列データ処理~ (Compass Booksシリーズ)
- 作者: 巣籠 悠輔
- 出版社/メーカー: マイナビ出版
- 発売日: 2019/11/27
- メディア: 単行本(ソフトカバー)
【Neural Network Console】LSTMを理解するため Elman_net を理解する [AI]
NNCは動画が充実していて本当に助かります。NNL (Nnabla) はもう少しなんとかならんですかねぇ…
で、この動画で、 LSTM を理解するには、Elman_net を理解するのがよろし!と師匠が言っているので、Elman_net を試してみました。見よう見真似で組んでみたネットワークがこちら。
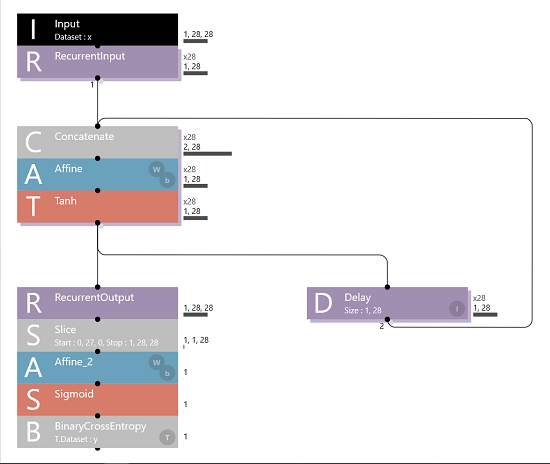
ここで、"RecurrentInput", "Slice" といったレイヤーが新顔なのでちょっと戸惑います。
■ ReccurentInput の説明 ReccurentInput は、Reccurent Neural Network のループの開始位置を指定します。 Axisは Time ループの軸を指定し、Time ループは Axis で指定された軸の長さになります。
(1,28,28) の長さの画像は 各行 (1,28) の一次元データを28回ループする形になりますので、Axis は "1" を指定します。
■ Slice の説明 Slice は配列の一部を抜き出します。
| Start | 抜き出す配列の開始位置を指定します。 |
| Stop | 抜き出す配列の終了位置を指定します。 |
| Step | 抜き出す配列の間隔を指定します。 例えば、"3, 48, 64" の画像の中心 "24 x 32" の縦横2ピクセル毎を抜き出す場合、 開始位置 "0, 12, 16" 、終了位置 "3, 36, 48" 、間隔"1, 2, 2" を指定します。 |
ここでは最終結果の一次元の28個の数列の結果、 "1, 1, 28" のデータが取り出せればよいので、開始位置は "0, 27, 0"、終了位置は ”1, 28, 28" を指定します。
テスト用のデータセットは、MNIST の ”4,9” 判別用のデータセットを使ってみました。学習の結果です。
-7c98a.png)
多少ばらついていますが、収束しているようです。結果を見てみます。
-1eb7f.png)
だいたい93%といったところですね。
一通り動かすことができたので、なんとなく理解が深まりました。
と、ここまでは教えてもらったことを試してみただけなので、あまり面白くありません。
せっかくなら Elman_net の各時間軸の出力結果を画像にして出力してみたいと思います。試しに次のようなネットワークを組んでみました。
-65eb1.png)
学習をさせてみると綺麗な曲線となりました。これは結果が期待できます。
-7397a.png)
こちらが出力結果です。
-31b1a.png)
おお、なかなかよい感じで出力が得られました。NNCだとこのようなことも簡単に試せるのでいいですね。 😀
(^^)/~
ソニー開発のNeural Network Console入門【増補改訂・クラウド対応版】--数式なし、コーディングなしのディープラーニング
- 出版社/メーカー: リックテレコム
- 発売日: 2018/11/14
- メディア: 単行本(ソフトカバー)
- 作者: 良一, 柴田
- 出版社/メーカー: 工学社
- 発売日: 2019/08/01
- メディア: 単行本

Excelでわかるディープラーニング超入門【RNN・DQN編】
- 出版社/メーカー: 技術評論社
- 発売日: 2019/05/10
- メディア: 単行本(ソフトカバー)
Neural Network Libraries (Nnabla) で作った AI を SPRESENSE で動かす! [AI]

SPRESENSEに動かすのはここで紹介したコードに次のコードを追記します。
■ Import に nnabla.util.save を追加
ネットワークをメディアに出力するためのユーティリティです。コードの冒頭に追加してください。
import nnabla.utils.save as Save
■ ネットワークをメディアに出力する
NNP というファイルを一旦出力します。フォーマットの詳細はよくわかりませんが、このチュートリアルを参考にしました。次のコードをPythonコードの最後に追加してください。
## save the model
contents = {
'networks' : [
{'name': 'sindet'
,'batch_size': batch_size
,'outputs': {'result': result}
,'names' : {'input': input_data}
}
]
,
'executors' : [
{'name': 'runtime'
,'network': 'sindet'
,'data': ['input']
,'output': ['result']
}
]
}
Save.save('sindet.nnp', contents)
次にSPRESENSE が読み込めるようにここで保存したNNPデータを変換します。
■ NNPファイルをNNBに変換する
SPRESENSE で読み込めるようにするには "NNB" という形式に変換しなければなりません。コマンドラインアプリを使って変換することができます。詳しくはこちらを参照してください。
$ nnabla_cli convert -b 1 sindet.nnp sindet.nnb [nnabla][INFO]: Initializing CPU extension... NNabla command line interface (Version:1.7.0, Build:200401213820) Importing sindet.nnp Expanding sindet.
■ "sindet.nnb" を SDカードにコピーして SPRESENSE に差し込む
"sindet.nnb" というファイルが生成されるので、それをSDカードにコピーして、SPRESENSEの拡張ボードのSDカードスロットに差し込みましょう。
.png)
■ テスト用の Arduino スケッチを SPRESENSE に書き込みを動作確認をする
Arduino IDE を使って、テスト用の Arduino スケッチを書き込みます。SPRESENSE のコードも Python で書けると楽だなと思いましたが、 CircuitPython では まだ DNNRT ライブラリはサポートされていないみたいですね…。もう少し待ちましょう。
#include <SDHCI.h>
#include <DNNRT.h>
#include <math.h>
DNNRT dnnrt;
SDClass SD;
float input_data[64];
float output_data[64];
void setup() {
int ret;
Serial.begin(115200);
SD.begin();
File nnbfile = SD.open("sindet.nnb");
if (!nnbfile) {
Serial.println("nnb not found");
return;
}
ret = dnnrt.begin(nnbfile);
if (ret < 0) {
Serial.println("DNNRT initialization failure: " + String(ret));
return;
}
DNNVariable input(64);
float *d = input.data();
for (int i = 0; i < 64; ++i) {
d[i] = input_data[i] = sin(i/10.0) + float(random(-3, 4))/10.0;
}
dnnrt.inputVariable(input, 0);
dnnrt.forward();
DNNVariable output = dnnrt.outputVariable(0);
Serial.print("sin,");
Serial.print("input,");
Serial.println("output");
for (int i = 0; i < 64; ++i) {
Serial.print(String(sin(i/10.0)) + ",");
Serial.print(String(input_data[i]) + ",");
Serial.println(String(output[i]));
}
dnnrt.end();
}
void loop() {
// put your main code here, to run repeatedly:
}
結果を見てみましょう!
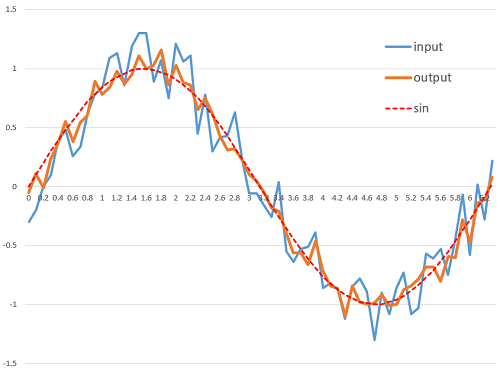
おお、いい感じに出ました!うまくいきましたね。これで、Neural Network Libraries で作った AI も SPRESENSE で動かすことができるようになりました!😆
(^^)/~
ソニー開発のNeural Network Console入門【増補改訂・クラウド対応版】--数式なし、コーディングなしのディープラーニング
- 出版社/メーカー: リックテレコム
- 発売日: 2018/11/14
- メディア: 単行本(ソフトカバー)

SONY SPRESENSE メインボード CXD5602PWBMAIN1
- 出版社/メーカー: スプレッセンス(Spresense)
- メディア: Tools & Hardware

SONY SPRESENSE 拡張ボード CXD5602PWBEXT1
- 出版社/メーカー: スプレッセンス(Spresense)
- メディア: Tools & Hardware
Neural Network Libraries (Nnabla) を使って「Auto Encoder」を実装してみた! [AI]
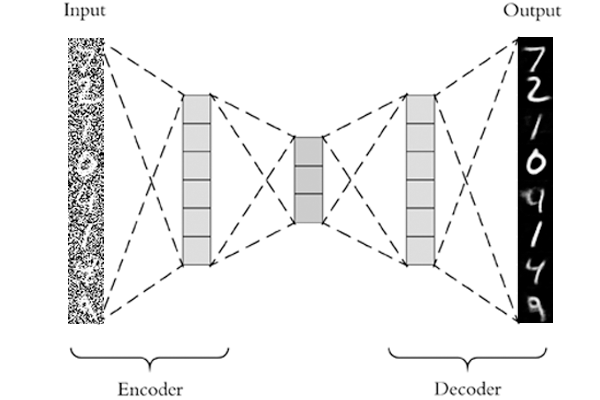
Auto Encoder は Deep Learning の中では比較的簡単なものですので、入門にはちょうど良い例題だと思います。(もうちょっと簡単にできるとよかったのですが…)
今回、学習させるデータはSin波です。トレーニングデータは、Sin派に±0.3のノイズを加えて生成しました。まずは Python のコードの全体を貼っておきます。(そのうち github に上げます)
# neural network libraries
import nnabla as nn
import nnabla.functions as F
import nnabla.parametric_functions as PF
import nnabla.solvers as S
# other libraries
import random
import numpy as np
import matplotlib.pyplot as plt
# define the neural network
def network(y):
h = PF.affine(y, 256, name = "a1")
h = F.relu(h)
h = PF.affine(y, 128, name = "a2")
h = F.relu(h)
h = PF.affine(h, 32, name = "a3")
h = F.relu(h)
h = PF.affine(y, 128, name = "a4")
h = F.relu(h)
h = PF.affine(h, 256, name = "a5")
h = F.relu(h)
h = PF.affine(h, 64, name = 'a6')
return h
## setup neuralnetwork
nn.clear_parameters()
batch_size = 1
input_teacher_data = nn.Variable((batch_size, 64))
input_training_data = nn.Variable((batch_size, 64))
output_data = network(input_test_data)
## setup loss function
#loss = F.mean(F.squared_error(output_data, input_teacher_data))
loss = F.mean(F.squared_error(output_data, input_training_data))
solver = S.Adam()
solver.set_parameters(nn.get_parameters())
## generate teacher data
x = [n for n in np.arange(0.0, 6.4, 0.1)]
teacher_data = [np.sin(n) for n in x]
## for graph plot
loss_list = []
step = []
y_list = []
## do training
epoch = 1000
for i in range(epoch):
# generate training data
training_data = [np.sin(n) + random.uniform(-0.3, 0.3) for n in x]
y_list.append(training_data)
#input_teacher_data.d = teacher_data
input_training_data.d = training_data
# do deep learning
loss.forward()
solver.zero_grad()
loss.backward()
solver.update()
loss_list.append(loss.d.copy())
step.append(i)
## display test data
for i in range(epoch):
plt.plot(x, y_list[i])
plt.title("Training Data")
plt.grid(True)
plt.show()
## display training progress
plt.plot(step, loss_list)
plt.title("Training Error")
plt.xlabel("step")
plt.ylabel("loss")
plt.grid(True)
plt.show()
## generate validation data
val_data = [np.sin(n) + random.uniform(-0.3, 0.3) for n in x]
## do inference
batch_size = 1
input_data = nn.Variable((batch_size, 64))
result = network(input_data)
input_data.d = val_data
result.forward()
output = result.d.copy().reshape(64,).tolist()
## display the result
sin = [np.sin(n) for n in x]
plt.plot(x, val_data, label="input data")
plt.plot(x, output, label="result data", linewidth=3.0)
plt.plot(x, sin, label="sin data", color="red", linestyle="dashed")
plt.legend()
plt.title("Input and Result")
plt.grid(True)
plt.show()
ここから細かくコードを解説していきます。(トーシローなんで間違っているかも知れません。もし間違っていたら指摘いただけると助かります)
■ Import する各種ライブラリ
nnabla の各種ライブラリと、numpyとグラフを表示のための matplot をインポートします。
# neural network libraries import nnabla as nn import nnabla.functions as F import nnabla.parametric_functions as PF import nnabla.solvers as S # other libraries import random import numpy as np import matplotlib.pyplot as plt
■ AutoEncoder のニューラルネットワークを構築する
Auto Encoder は Affine と Relu で構成してみました。層やノードの数は適当に決めています。適当に値を変えてみたり、活性化関数を変えてみて様子を見てみると面白いかもしれません。
# define the neural network
def network(y):
h = PF.affine(y, 256, name = "a1")
h = F.relu(h)
h = PF.affine(y, 128, name = "a2")
h = F.relu(h)
h = PF.affine(h, 32, name = "a3")
h = F.relu(h)
h = PF.affine(y, 128, name = "a4")
h = F.relu(h)
h = PF.affine(h, 256, name = "a5")
h = F.relu(h)
h = PF.affine(h, 64, name = 'a6')
return h
■ ニューラルネットワークをセットアップする
・Nnabla のパラメータの消去
nnabla が保持しているパラメータをnn.clear_parameters()で消去しておきます。これがないと、ニューラルネットの構成を変えるとエラーが出ます。
・バッチサイズの指定
batch_size は1にしてみました。都度データを生成して学習させるので、複数のデータを一度に与えるのが面倒だったからというのが真相です。
・コンテナの定義
nn.Variableは、ニューラルネットにデータを渡すためのコンテナです。学習や推論を行うときはデータをこのコンテナに格納して渡します。
## setup neuralnetwork nn.clear_parameters() batch_size = 1 input_teacher_data = nn.Variable((batch_size, 64)) input_training_data = nn.Variable((batch_size, 64)) output_data = network(input_test_data)
■ 損失関数をセットアップする
ここでは損失関数と学習を進めるための Solver を設定します。Solver は平たく言えば最小二乗法のような損失を小さくするための数学的な道具です。
・損失関数:F.mean(F.squared_error(output_data, input_training_data))
ここでは出力値と入力値の二乗平均誤差を出しています。いわゆる教師なし学習です。コメントアウトしているコードは、入力データに誤差のない純粋な Sin波を教師データとして与えています。教師ありと教師無しデータでどのように結果が違うかぜひ試してみてください。
・ソルバー:S.Adam()
正直よく知りません。与えるパラメータが少なく便利なので使ってみました。他のソルバーで試してみて結果がどう変わるか観察してみると面白いかもしれません。詳しくはこちらを参照してください。
## setup loss function #loss = F.mean(F.squared_error(output_data, input_teacher_data)) loss = F.mean(F.squared_error(output_data, input_training_data)) solver = S.Adam() solver.set_parameters(nn.get_parameters())
■ 教師データならびにグラフ描画用の変数の設定
教師データを使った学習を行う場合は、teacher_data を使ってください。他はグラフプロット用の変数宣言です。
## generate teacher data x = [n for n in np.arange(0.0, 6.4, 0.1)] #teacher_data = [np.sin(n) for n in x] ## for graph plot loss_list = [] step = [] y_list = []
■ 学習(ディープラーニング)用のループ処理
学習回数(Epoch)は1000回としました。
・学習用データを生成
training_data = [np.sin(n) + random.uniform(-0.3, 0.3) for n in x] がそれにあたります。少しトリッキーなコードですが、0.0~6.3 までのサインデータに±0.3 のランダムデータを加えて学習用データとしています。
・コンテナの学習用データを格納
input_training_data.d = training_data で、コンテナに学習用データを設定しています。こうすることで、ニューラルネットワークにデータを渡すことができます。
・学習を実施
loss.forward() / solver.zero_grad() / loss.backward() / solver.update() が学習の基本ルーチンと思ってください。損失関数で値を出して、前回との差分を勾配降下法で逆伝搬させパラメータを調整して差を縮めていくという処理です。使う側にとっては、この程度の理解で十分かと。
## do training
epoch = 1000
for i in range(epoch):
# generate training data
training_data = [np.sin(n) + random.uniform(-0.3, 0.3) for n in x]
y_list.append(training_data)
#input_teacher_data.d = teacher_data
input_training_data.d = training_data
# do deep learning
loss.forward()
solver.zero_grad()
loss.backward()
solver.update()
loss_list.append(loss.d.copy())
step.append(i)
■ 推論を実行する
学習が終わったので、推論を実行します。
・テスト用データの生成
val_data = [np.sin(n) + random.uniform(-0.3, 0.3) for n in x] で学習用データと同じ要領でデータ生成します。
・ニューラルネットワークの設定
input_data = nn.Variable((batch_size, 64)) , result = network(input_data) で、コンテナの準備とニューラルネットワークの設定を行います。
・推論を実行
input_data.d = val_data でテスト用データをコンテナに格納し、 result.forward() で推論が実行されます。
・出力データを取得
出力したデータの次元は (1, 64) になっているので、output = result.d.copy().reshape(64,).tolist() で出力を 64要素を持つリストにして出力します。グラフに描画するための処理です。
## generate validation data val_data = [np.sin(n) + random.uniform(-0.3, 0.3) for n in x] ## do inference batch_size = 1 input_data = nn.Variable((batch_size, 64)) result = network(input_data) input_data.d = val_data result.forward() output = result.d.copy().reshape(64,).tolist()
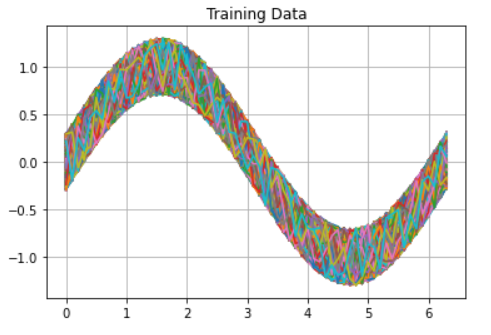
■ 出力結果をみてみる
学習用データをすべてグラフにマップしたものです。このデータを使って学習しました。
学習の過程を示したグラフです。うまく収束しているみたいですね。
-ba202.png)
これが結果です。青がテスト用データ。オレンジが AutoEncoder の出力。点線が純粋な Sin波です。
-b038c.png)
結果はまぁまぁかな。教師ありでの学習もぜひ試してみてください。もっと良い結果が出ると思います。🙂
(^^)/~
ソニー開発のNeural Network Console入門【増補改訂・クラウド対応版】--数式なし、コーディングなしのディープラーニング
- 出版社/メーカー: リックテレコム
- 発売日: 2018/11/14
- メディア: 単行本(ソフトカバー)
- 作者: 良一, 柴田
- 出版社/メーカー: 工学社
- 発売日: 2019/08/01
- メディア: 単行本

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
- 作者: 斎藤 康毅
- 出版社/メーカー: オライリージャパン
- 発売日: 2016/09/24
- メディア: 単行本(ソフトカバー)
ys_taro さん

-
nice! 35196
記事 1099
テーマ 趣味・カルチャー
プロフィール
Contact Me


