TensorFlow Core tutorial を学んでみた(2)~ tf.train API~ [AI]
TensorFlow の Core tutorial で紹介されている train API について学んでみました。
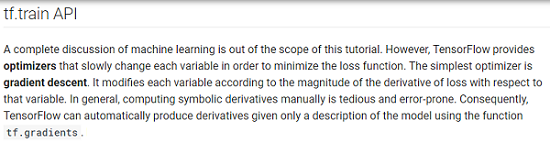
https://www.tensorflow.org/get_started/get_started#tftrain_api
train API は、損失関数である差分二乗和を最小する係数を求めていくための関数です。前回、以下の関数を考えてみました。
この時に、与えられた x, y の値から loss が最小となるように W と b の値をかえていくのが train API の機能です。いくつか手法があるようですが、Core tutorial では Gradient Descent (勾配降下法) が使われています。
引数は学習係数(learning rate)で、この数値を変えることで学習速度が変わるようです。学習の様子を確認するためのサンプルコードを作ってみました。
学習係数を変えながら出力をしてみました。まずは係数を減らしてみます。学習係数を減らしていくとloss の減り方が緩やかになっているのが分かります。
今度は逆に係数を増やしてみました。
0.02までは早く収束していますが、0.03から不安定になり、0.04では発散してしまいました。制御係数と同じで値を大きくしていくと発散しやすくなるようです。
当然、モデルによって最適な学習係数は変わりますが、この値は経験値で求めるのしかないのかな。その辺りも追々調べていきたいと思います。
(^_^)/~
")

")
https://www.tensorflow.org/get_started/get_started#tftrain_api
train API は、損失関数である差分二乗和を最小する係数を求めていくための関数です。前回、以下の関数を考えてみました。
x = [1, 2, 3, 4] y = [0, -1, -2, -3] squared_deltas = (W * x + b) - y) * ((W * x + b) - y ) loss = SUM(squared_deltas)
この時に、与えられた x, y の値から loss が最小となるように W と b の値をかえていくのが train API の機能です。いくつか手法があるようですが、Core tutorial では Gradient Descent (勾配降下法) が使われています。
引数は学習係数(learning rate)で、この数値を変えることで学習速度が変わるようです。学習の様子を確認するためのサンプルコードを作ってみました。
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
# define variables with initial value
W = tf.Variable([0.3], dtype=tf.float32)
b = tf.Variable([-0.3], dtype=tf.float32)
# Model input and output
x = tf.placeholder(tf.float32)
linear_model = W * x + b
y = tf.placeholder(tf.float32)
# loss
loss = tf.reduce_sum(tf.square(linear_model - y))
# set learning rate to gradient decent optimizer
learning_rate = 0.01
print("learning rate: %s"%learning_rate)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train = optimizer.minimize(loss)
# training data
x_train = [1, 2, 3, 4]
y_train = [0, -1, -2, -3]
# traing loop
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# create exection instance
sess = tf.Session()
# initialize variables
init = tf.global_variables_initializer()
sess.run(init)
# initial
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 1st training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 2nd training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 3rd training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 4th training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 5th training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 6th training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 7th training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 8th training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 9th training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
# 10th training
for i in range(100):
sess.run(train, {x: x_train, y: y_train})
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
学習係数を変えながら出力をしてみました。まずは係数を減らしてみます。学習係数を減らしていくとloss の減り方が緩やかになっているのが分かります。
C:\Users\Taro\Documents\TensorFlow>python trainapi.py learning rate: 0.01 W: [ 0.30000001] b: [-0.30000001] loss: 23.66 W: [-0.84079814] b: [ 0.53192717] loss: 0.146364 W: [-0.95227844] b: [ 0.85969269] loss: 0.0131513 W: [-0.98569524] b: [ 0.95794231] loss: 0.00118168 W: [-0.99571204] b: [ 0.98739296] loss: 0.000106178 W: [-0.99871475] b: [ 0.99622124] loss: 9.5394e-06 W: [-0.99961478] b: [ 0.99886739] loss: 8.56873e-07 W: [-0.99988455] b: [ 0.99966055] loss: 7.69487e-08 W: [-0.99996537] b: [ 0.99989825] loss: 6.90848e-09 W: [-0.99998957] b: [ 0.99996936] loss: 6.24471e-10 W: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11 C:\Users\Taro\Documents\TensorFlow>python trainapi.py learning rate: 0.005 W: [ 0.30000001] b: [-0.30000001] loss: 23.66 W: [-0.70869172] b: [ 0.14351812] loss: 0.490055 W: [-0.84021938] b: [ 0.53022552] loss: 0.14743 W: [-0.91236132] b: [ 0.74233174] loss: 0.0443537 W: [-0.95193082] b: [ 0.85867071] loss: 0.0133436 W: [-0.97363442] b: [ 0.92248183] loss: 0.00401434 W: [-0.9855386] b: [ 0.95748174] loss: 0.0012077 W: [-0.99206799] b: [ 0.97667885] loss: 0.000363336 W: [-0.99564934] b: [ 0.98720855] loss: 0.000109307 W: [-0.99761379] b: [ 0.99298412] loss: 3.2883e-05 W: [-0.9986912] b: [ 0.99615198] loss: 9.89192e-06 C:\Users\Taro\Documents\TensorFlow>python trainapi.py learning rate: 0.001 W: [ 0.30000001] b: [-0.30000001] loss: 23.66 W: [-0.52810556] b: [-0.3849203] loss: 1.28182 W: [-0.58207232] b: [-0.22875588] loss: 1.00865 W: [-0.62926829] b: [-0.08999654] loss: 0.793704 W: [-0.67113376] b: [ 0.03309342] loss: 0.624565 W: [-0.70827162] b: [ 0.14228313] loss: 0.491469 W: [-0.74121565] b: [ 0.2391424] loss: 0.386737 W: [-0.77043933] b: [ 0.32506362] loss: 0.304323 W: [-0.796363] b: [ 0.40128195] loss: 0.239471 W: [-0.819359] b: [ 0.46889341] loss: 0.188439 W: [-0.83975828] b: [ 0.52886957] loss: 0.148283
今度は逆に係数を増やしてみました。
C:\Users\Taro\Documents\TensorFlow>python trainapi.py learning rate: 0.01 W: [ 0.30000001] b: [-0.30000001] loss: 23.66 W: [-0.84079814] b: [ 0.53192717] loss: 0.146364 W: [-0.95227844] b: [ 0.85969269] loss: 0.0131513 W: [-0.98569524] b: [ 0.95794231] loss: 0.00118168 W: [-0.99571204] b: [ 0.98739296] loss: 0.000106178 W: [-0.99871475] b: [ 0.99622124] loss: 9.5394e-06 W: [-0.99961478] b: [ 0.99886739] loss: 8.56873e-07 W: [-0.99988455] b: [ 0.99966055] loss: 7.69487e-08 W: [-0.99996537] b: [ 0.99989825] loss: 6.90848e-09 W: [-0.99998957] b: [ 0.99996936] loss: 6.24471e-10 W: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11 C:\Users\Taro\Documents\TensorFlow>python trainapi.py learning rate: 0.02 W: [ 0.30000001] b: [-0.30000001] loss: 23.66 W: [-0.95297438] b: [ 0.8617391] loss: 0.0127705 W: [-0.99583626] b: [ 0.98775804] loss: 0.000100119 W: [-0.9996314] b: [ 0.99891615] loss: 7.84759e-07 W: [-0.9999674] b: [ 0.99990404] loss: 6.14229e-09 W: [-0.99999708] b: [ 0.99999142] loss: 4.92442e-11 W: [-0.99999952] b: [ 0.99999869] loss: 1.06581e-12 W: [-0.99999952] b: [ 0.99999869] loss: 1.06581e-12 W: [-0.99999952] b: [ 0.99999869] loss: 1.06581e-12 W: [-0.99999952] b: [ 0.99999869] loss: 1.06581e-12 W: [-0.99999952] b: [ 0.99999869] loss: 1.06581e-12 C:\Users\Taro\Documents\TensorFlow>python trainapi.py learning rate: 0.03 W: [ 0.30000001] b: [-0.30000001] loss: 23.66 W: [ 0.16820002] b: [ 1.35244703] loss: 49.6722 W: [ 0.73389339] b: [ 1.58857942] loss: 111.988 W: [ 1.60297251] b: [ 1.88529921] loss: 252.487 W: [ 2.90843058] b: [ 2.32934356] loss: 569.256 W: [ 4.86862707] b: [ 2.99604988] loss: 1283.44 W: [ 7.81191444] b: [ 3.9971242] loss: 2893.63 W: [ 12.23135185] b: [ 5.50027037] loss: 6523.96 W: [ 18.86728859] b: [ 7.75730085] loss: 14708.9 W: [ 28.83135033] b: [ 11.14629936] loss: 33162.6 W: [ 43.7927475] b: [ 16.23500061] loss: 74768.5 C:\Users\Taro\Documents\TensorFlow>python trainapi.py learning rate: 0.04 W: [ 0.30000001] b: [-0.30000001] loss: 23.66 W: [ 1.62939458e+22] b: [ 5.54192817e+21] loss: inf W: [ nan] b: [ nan] loss: nan W: [ nan] b: [ nan] loss: nan W: [ nan] b: [ nan] loss: nan W: [ nan] b: [ nan] loss: nan W: [ nan] b: [ nan] loss: nan W: [ nan] b: [ nan] loss: nan W: [ nan] b: [ nan] loss: nan W: [ nan] b: [ nan] loss: nan W: [ nan] b: [ nan] loss: nan
0.02までは早く収束していますが、0.03から不安定になり、0.04では発散してしまいました。制御係数と同じで値を大きくしていくと発散しやすくなるようです。
当然、モデルによって最適な学習係数は変わりますが、この値は経験値で求めるのしかないのかな。その辺りも追々調べていきたいと思います。
(^_^)/~
TensorFlowはじめました 実践!最新Googleマシンラーニング (NextPublishing)
- 出版社/メーカー: インプレスR&D
- 発売日: 2016/07/29
- メディア: Kindle版
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
- 作者: 斎藤 康毅
- 出版社/メーカー: オライリージャパン
- 発売日: 2016/09/24
- メディア: 単行本(ソフトカバー)
TensorFlow機械学習クックブック Pythonベースの活用レシピ60+ (impress top gear)
- 作者: Nick McClure
- 出版社/メーカー: インプレス
- 発売日: 2017/08/14
- メディア: 単行本(ソフトカバー)
ys_taro さん

-
nice! 35196
記事 1099
テーマ 趣味・カルチャー
プロフィール
Contact Me



む、難しい(;^ω^) 毎日、にらめっこしていれば、少しは分かるようになるかな(^^)
by ワンモア (2017-09-04 09:17)
AIはニューラルネットワークはそれほど難しくないのですけど、機械学習が入ると難しいのですよね。私もまだよく分かってません。σ^^;
by ys_oota (2017-09-05 00:28)
刺激を受けて Amazon でポチッと AI の入門書を買ってしまいました。
なんと仮想マシンをインストールして、そこに構築された環境で例題を実行するようになっており、Windows でも Linux ユーザーでも使えるようになっています。 でも、仮想マシンのインストールが手強い気がしています。
by ktm (2017-09-05 10:53)
ktmさん、やはりこれからの時代はAIですかね!
仮想マシンは Virtual Box でしょうか?ネットワークの設定がやや独特だった記憶がありますが、シリアルなどハードリソースを使わなければすんなり使えると思います。^^
by ys_oota (2017-09-05 23:43)
はい、それです。
AI で何するのと聞かれると困るのですが、第五世代コンピュータが持て囃された頃に比べて、今の AI は何が何処まで出来るようになったかの理解を深めたいと考えています。 (第五世代コンピュータは結局実用例がなく終わってしまいましたね)
世の中、Raspberry Pi で AI を動かしている方もおられるようです。
Raspberry Pi で AI を動かして、アマチュア無線の情報処理に応用できるかを妄想してみたいと思います。 あ、あくまで妄想レベルですから。
by ktm (2017-09-06 00:21)