TensorFlow MNIST For ML Beginners をやってみた(2) [AI]
TensorFlow MNIST For ML Beginners をやってみると使い方はわかりますが、理屈がわからないと気持ち悪いですよね。少し TensorFlow から話ははずれますが、Deep Learning の理屈について考えてみます。
ポイントは、損失関数と学習の仕組みです。損失関数を最小にするように学習するというのが Deep Learning の理屈ですが、これは蓋を開けてみると、最小二乗法で近似曲線を割り出す理屈と同じだったりします。
こちらのページが最も分かりやすかったです。
解けない連立方程式とディープラーニング
http://www.fward.net/archives/2126
ここで、上のサイトでサンプルに出ている行列を考えてみます。これは MNIST のミニチュア版といえます。
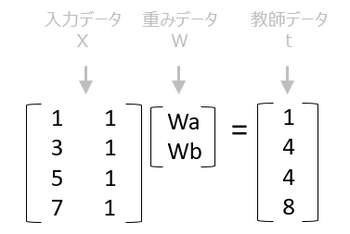
ここで、重みデータであるWを変数、損失関数を二乗誤差とすると二次曲線で表せます。このWの値を曲線の傾きに学習係数ηを掛けた分だけずらしていき、損失関数が最小になる曲率ゼロまで近づけていきます。
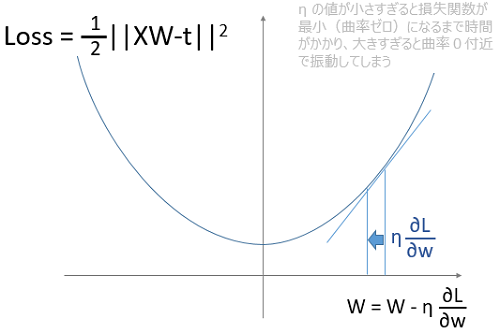
この学習係数ηは、結構くせもので図を見てもわかるように、小さすぎると学習ステップを多くしなければならないですし、大きすぎると曲率ゼロ付近で振動をしてしまいます。
さて理屈は分かったのですが、せっかくなのでプログラムを作って検証したいところです。そこで損失関数の微分値の式を導出してみましょう。行列の微分なのでちょっとやっかいです。
最初に損失関数を展開します。絶対値なので、転置行列と行列の積になることに注意します。
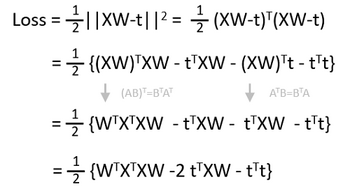
さて、微分をしてみましょう。行列の微分には公式があります。こちらのサイトがよくまとまっています。
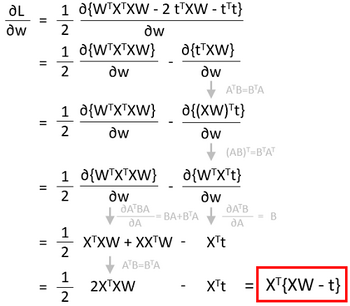
ということで損失関数の微分は、Xの転置行列に教師データと計算値の誤差を掛けたものになりました。
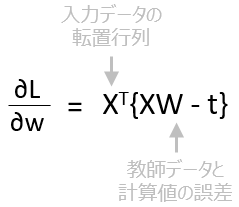
それにηをかけてWの値を更新します。
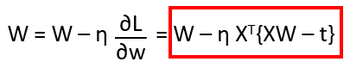
これを python のプログラムにしてみました。η は 0.0229 と設定しています。
これを実行すると以下のようになります。
1174回目で損失関数が最小になり、値は1.35。Wa は 1.05、Wb は 0.05 になりました。解説サイトの数値とあっていますね。
これで、学習の実態はわかりました。損失関数や学習ステップ、学習係数が把握できたところで次のステップに進みますか。あーすっきりした。
(*^_^*)


")
ポイントは、損失関数と学習の仕組みです。損失関数を最小にするように学習するというのが Deep Learning の理屈ですが、これは蓋を開けてみると、最小二乗法で近似曲線を割り出す理屈と同じだったりします。
こちらのページが最も分かりやすかったです。
解けない連立方程式とディープラーニング
http://www.fward.net/archives/2126
ここで、上のサイトでサンプルに出ている行列を考えてみます。これは MNIST のミニチュア版といえます。

ここで、重みデータであるWを変数、損失関数を二乗誤差とすると二次曲線で表せます。このWの値を曲線の傾きに学習係数ηを掛けた分だけずらしていき、損失関数が最小になる曲率ゼロまで近づけていきます。
この学習係数ηは、結構くせもので図を見てもわかるように、小さすぎると学習ステップを多くしなければならないですし、大きすぎると曲率ゼロ付近で振動をしてしまいます。
さて理屈は分かったのですが、せっかくなのでプログラムを作って検証したいところです。そこで損失関数の微分値の式を導出してみましょう。行列の微分なのでちょっとやっかいです。
最初に損失関数を展開します。絶対値なので、転置行列と行列の積になることに注意します。
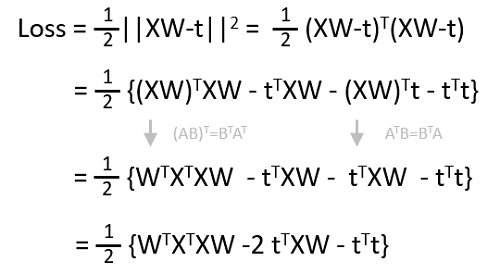
さて、微分をしてみましょう。行列の微分には公式があります。こちらのサイトがよくまとまっています。
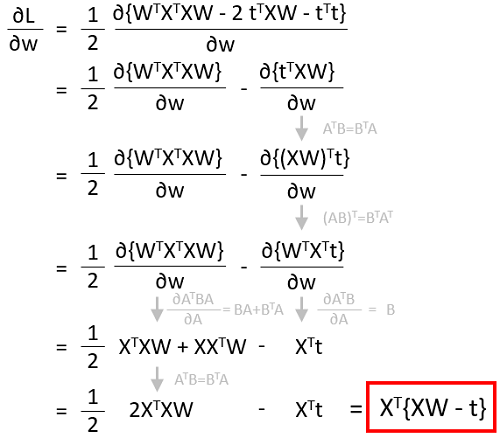
ということで損失関数の微分は、Xの転置行列に教師データと計算値の誤差を掛けたものになりました。

それにηをかけてWの値を更新します。
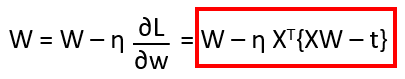
これを python のプログラムにしてみました。η は 0.0229 と設定しています。
import numpy as np
import math
X = np.array([[1,1], [3,1], [5,1], [7,1]], dtype="float").reshape((4, 2))
w = np.array([1, 1], dtype="float").reshape((2,1))
t = np.array([1, 4, 4, 8], dtype="float").reshape((4,1))
L = np.dot(X,w) - t # X*w - t
Loss = (sum(np.power(L,2))/2).round(8) # ||X*W - t||^2 / 2
preLoss = Loss
print(Loss)
eta = 0.0229
for i in range(5000):
dL = np.dot(X.T,(np.dot(X,w) - t)) # XT*{XW - t}
w = w - np.dot(eta,dL) # W = W - eta*dL/dw
L = np.dot(X,w) - t
Loss = (sum(np.power(L,2))/2).round(8)
if preLoss <= Loss:
break;
preLoss = Loss
print(Loss)
print(i)
print(Loss)
print(w)
これを実行すると以下のようになります。
1174 [ 1.35000079] [[ 1.04986813] [ 0.0499746 ]]
1174回目で損失関数が最小になり、値は1.35。Wa は 1.05、Wb は 0.05 になりました。解説サイトの数値とあっていますね。
これで、学習の実態はわかりました。損失関数や学習ステップ、学習係数が把握できたところで次のステップに進みますか。あーすっきりした。
(*^_^*)
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
- 作者: 斎藤 康毅
- 出版社/メーカー: オライリージャパン
- 発売日: 2016/09/24
- メディア: 単行本(ソフトカバー)
- 作者: 涌井 良幸
- 出版社/メーカー: 技術評論社
- 発売日: 2017/03/28
- メディア: 単行本(ソフトカバー)
TensorFlowはじめました 実践!最新Googleマシンラーニング (NextPublishing)
- 出版社/メーカー: インプレスR&D
- 発売日: 2016/07/29
- メディア: Kindle版
ys_taro さん

-
nice! 35196
記事 1099
テーマ 趣味・カルチャー
プロフィール
Contact Me



解説サイトみてなんかワクワクしてきましたが、
自分が使いこなすには無理かなぁ(笑)
でも、現実世界で4点の一番近くを通過する直線を導き出すには、
人間の直感や感覚が一番早いあぁと考えると、人間の脳って凄いなぁと思います(^^)AIはどこまで近づいてくるのかな。
by ワンモア (2017-09-30 22:50)
人間の感覚ってすごいですよね。コンピューターでは簡単な問題でも1000回以上学習しないといけないですが、人なら一瞬ですから。逐次処理するしかないコンピューターと空間を把握できる人間の差でしょうか。でも、最近は逐次処理が恐ろしく早いので、だんだん差がなくなってきていますが。。。(苦笑
by ys_oota (2017-10-01 00:26)